
本文主要探讨现阶段浏览器端可行的实时通信方案,以及它们的发展历史。
这里以sockjs作为切入点,这是一个流行的浏览器实时通信库,提供了'类Websocket'、一致性、跨平台的API,旨在浏览器和服务器之间创建一个低延迟、全双工、支持跨域的实时通信信道. 主要特点就是仿生Websocket,它会优先使用Websocket作为传输层,在不支持WebSocket的环境回退使用其他解决方案,例如XHR-Stream、轮询.
所以sockjs本身就是浏览器实时通信方案的编年史, 本文也是按照由新到老这样的顺序来介绍这些解决方案.
类似sockjs的解决方案还有 socket.io如果你觉得文章不错,请不要吝惜你的点赞👍,鼓励笔者写出更精彩的文章
目录
WebSocket
WebSocket其实不是本文的主角,而且网上已经有很多教程,本文的目的是介绍WebSocket之外的一些回退方案,在浏览器不支持Websocket的情况下, 可以选择回退到这些方案.
在此介绍Websocket之前,先来了解一些HTTP的基础知识,毕竟WebSocket本身是借用HTTP协议实现的。
HTTP协议是基于TCP/IP之上的应用层协议,也就是说HTTP在TCP连接中进行请求和响应的,浏览器会为每个请求建立一个TCP连接,请求等待服务端响应,在服务端响应后关闭连接:
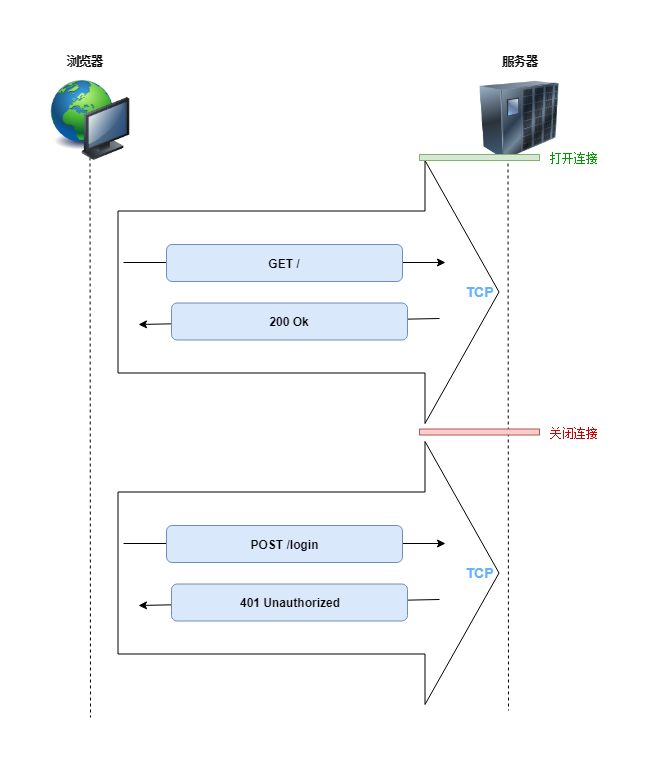
后来人们发现为每个HTTP请求都建立一个TCP连接,太浪费资源了,能不能不要着急关闭TCP连接,而是将它复用起来, 在一个TCP连接中进行多次请求。
这就有了HTTP持久连接(HTTP persistent connection, 也称为HTTP keep-alive), 它利用同一个TCP连接来发送和接收多个HTTP请求/响应。持久连接的方式可以大大减少等待时间, 双方不需要重新运行TCP握手,这对前端静态资源的加载也有很大意义:
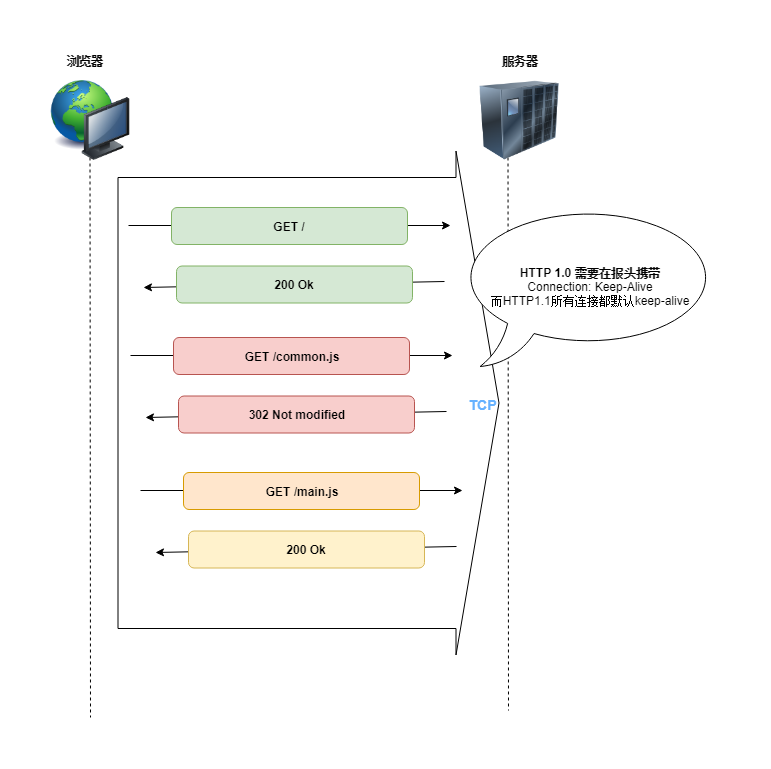
Ok, 现在回到WebSocket, 浏览器端用户程序并不支持和服务端直接建立TCP连接,但是上面我们看到每个HTTP请求都会建立TCP连接, TCP是可靠的、全双工的数据通信通道,那我们何不直接利用它来进行实时通信? 这就是Websocket的原理!
我们这里通过一张图,通俗地理解一下Websocket的原理:
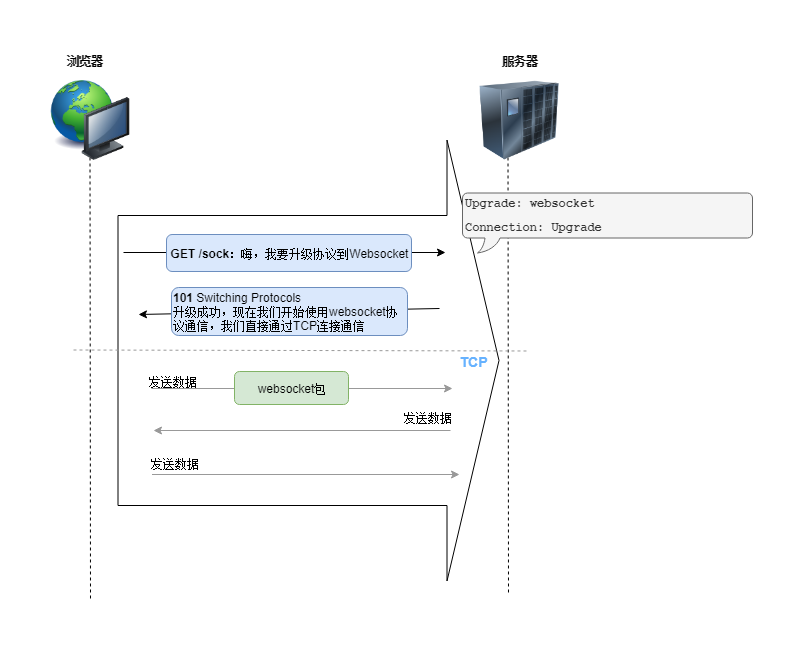
通过上图可以看到,WebSocket除最初建立连接时需要借助于现有的HTTP协议,其他时候直接基于TCP完成通信。这是浏览器中最靠近套接字的API,可以实时和服务端进行全双工通信. WebSocket相比传统的浏览器的Comet)(下文介绍)技术, 有很多优势:
- 更强的实时性。基于TCP协议的全双工通信
- 更高效。一方面是数据包相对较小,另一方面相比传统XHR-Streaming和轮询方式更加高效,不需要重复建立TCP连接
- 更好的二进制支持。 Websocket定义了二进制帧,相对HTTP,可以更轻松地处理二进制内容
- 保持连接状态。 相比HTTP无状态的协议,WebSocket只需要在建立连接时携带认证信息,后续的通信都在这个会话内进行
- 可以支持扩展。Websocket定义了扩展,用户可以扩展协议、实现部分自定义的子协议。如部分浏览器支持压缩等
它的接口也非常简单:
const ws = new WebSocket('ws://localhost:8080/socket');
// 错误处理
ws.onerror = (error) => { ... }
// 连接关闭
ws.onclose = () => { ... }
// 连接建立
ws.onopen = () => {
// 向服务端发送消息
ws.send("ping");
}
// 接收服务端发送的消息
ws.onmessage = (msg) => {
if(msg.data instanceof Blob) {
// 处理二进制信息
processBlob(msg.data);
} else {
// 处理文本信息
processText(msg.data);
}
}本文不会深入解析Websocket的协议细节,有兴趣的读者可以看下列文章:
如果不考虑低版本IE,基本上WebSocket不会有什么兼容性上面的顾虑. 下面列举了Websocket一些常见的问题, 当无法正常使用Websocket时,可以利用sockjs或者socket.io这些方案回退到传统的Comet技术方案.
-
浏览器兼容性。
- IE10以下不支持
- Safari 下不允许使用非标准接口建立连接
- 心跳. WebSocket本身不会维护心跳机制,一些Websocket实现在空闲一段时间会自动断开。所以sockjs这些库会帮你维护心跳
- 一些负载均衡或代理不支持Websocket。
- 会话和消息队列维护。这些不是Websocket协议的职责,而是应用的职责。sockjs会为每个Websocket连接维护一个会话,且这个会话里面会维护一个消息队列,当Websocket意外断开时,不至于丢失数据
XHR-streaming
XHR-Streming, 中文名称‘XHR流’, 这是WebSocket的最佳替补方案. XHR-streaming的原理也比较简单:服务端使用分块传输编码(Chunked transfer encoding)的HTTP传输机制进行响应,并且服务器端不终止HTTP响应流,让HTTP始终处于持久连接状态,当有数据需要发送给客户端时再进行写入数据。
没理解?没关系,我们一步一步来, 先来看一下正常的HTTP请求处理是这样的:
// Node.js代码
const http = require('http')
const server = http.createServer((req, res) => {
res.writeHead(200, {
'Content-Type': 'text/plain', // 设置内容格式
'Content-Length': 11, // 设置内容长度
})
res.end('hello world') // 响应
})客户端会立即接收到响应:
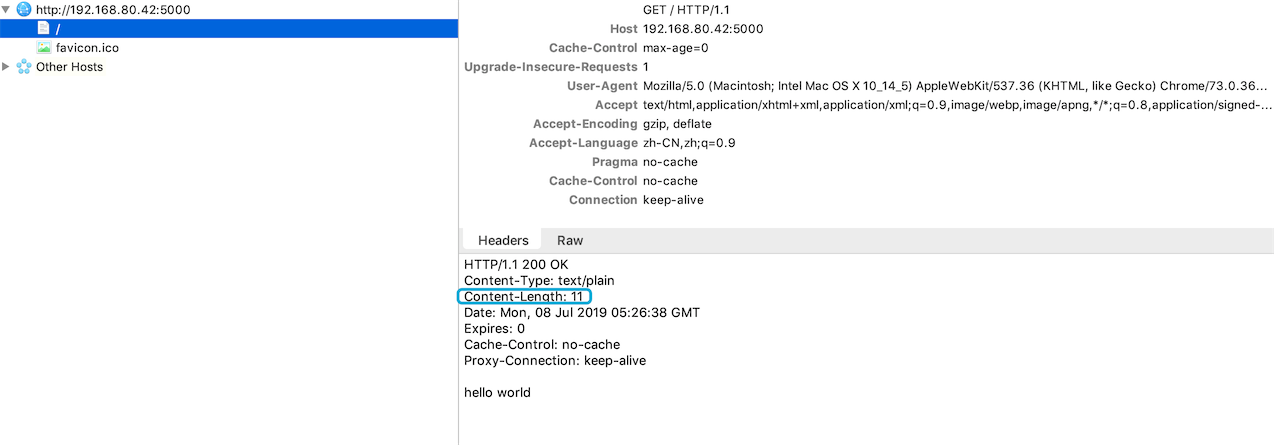
那么什么是分块传输编码呢?
在HTTP/1.0之前, 响应是必须作为一整块数据返回客户端的(如上例),这要求服务端在发送响应之前必须设置Content-Length, 浏览器知道数据的大小后才能确定响应的结束时间。这让服务器响应动态的内容变得非常低效,它必须等待所有动态内容生成完,再计算Content-Length, 才可以发送给客户端。如果响应的内容体积很大,需要占用很多内存空间.
HTTP/1.1引入了Transfer-Encoding: chunked;报头。 它允许服务器发送给客户端应用的数据可以分为多个部分, 并以一个或多个块发送,这样服务器可以发送数据而不需要提前计算发送内容的总大小。
有了分块传输机制后,动态生成内容的服务器就可以维持HTTP长连接, 也就是说服务器响应流不结束,TCP连接就不会断开.
现在我们切换为分块传输编码模式, 且我们不终止响应流,看会有什么情况:
const http = require('http')
const server = http.createServer((req, res) => {
res.writeHead(200, {
'Content-Type': 'text/plain'
// 'Content-Length': 11, // 🔴将Content-Length报头去掉,Node.js默认就是使用分块编码传输的
})
res.write('hello world')
// res.end() // 🔴不终止输出流
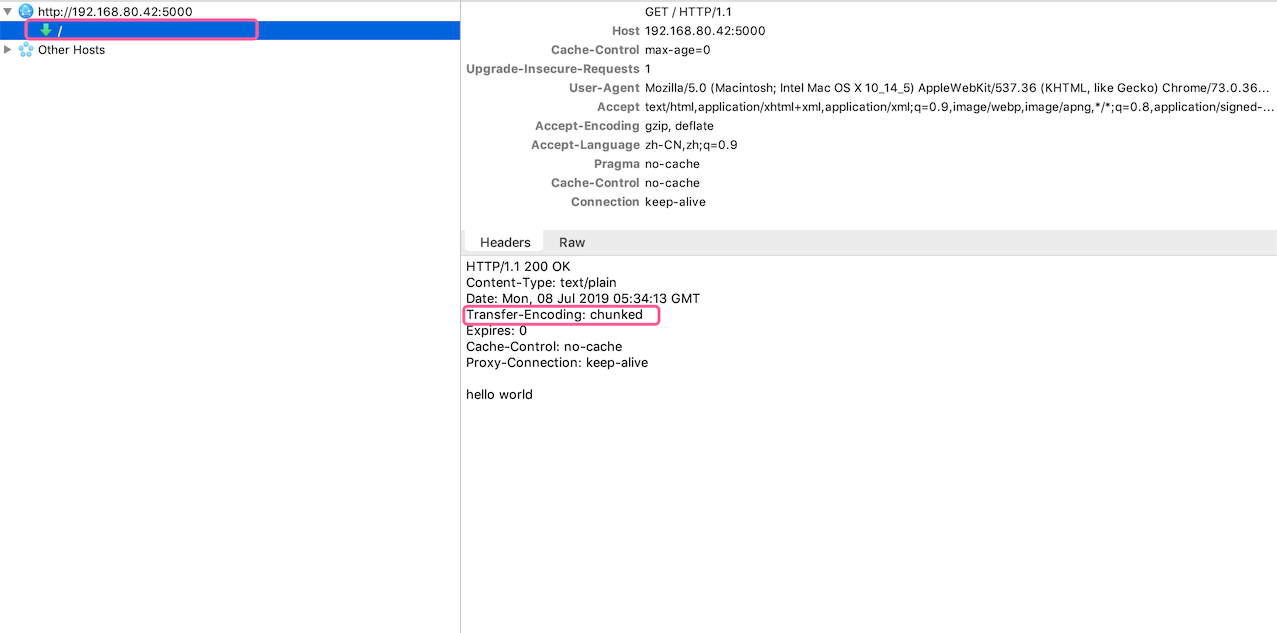
})我们会发现请求会一直处于Pending状态(绿色下载图标),除非出现异常、服务器关闭或显式关闭连接(比如设置超时机制),请求是永远不会终止的。但是即使处于Pending状态客户端还是可以接收数据,不必等待请求结束:
基于这个原理我们再来创建一个简单的ping-pong服务器:
const server = http.createServer((req, res) => {
if (req.url === '/ping') {
// ping请求
if (pendingResponse == null) {
res.writeHead(500);
res.write('session not found');
res.end();
return;
}
res.writeHead(200)
res.end()
// 给客户端推流
pendingResponse.write('pong\n');
} else {
// 保存句柄
res.writeHead(200, {
'Content-Type': 'text/plain',
});
res.write('welcome to ping\n');
pendingResponse = res
}
});测试一下,在另一个窗口访问/ping路径:
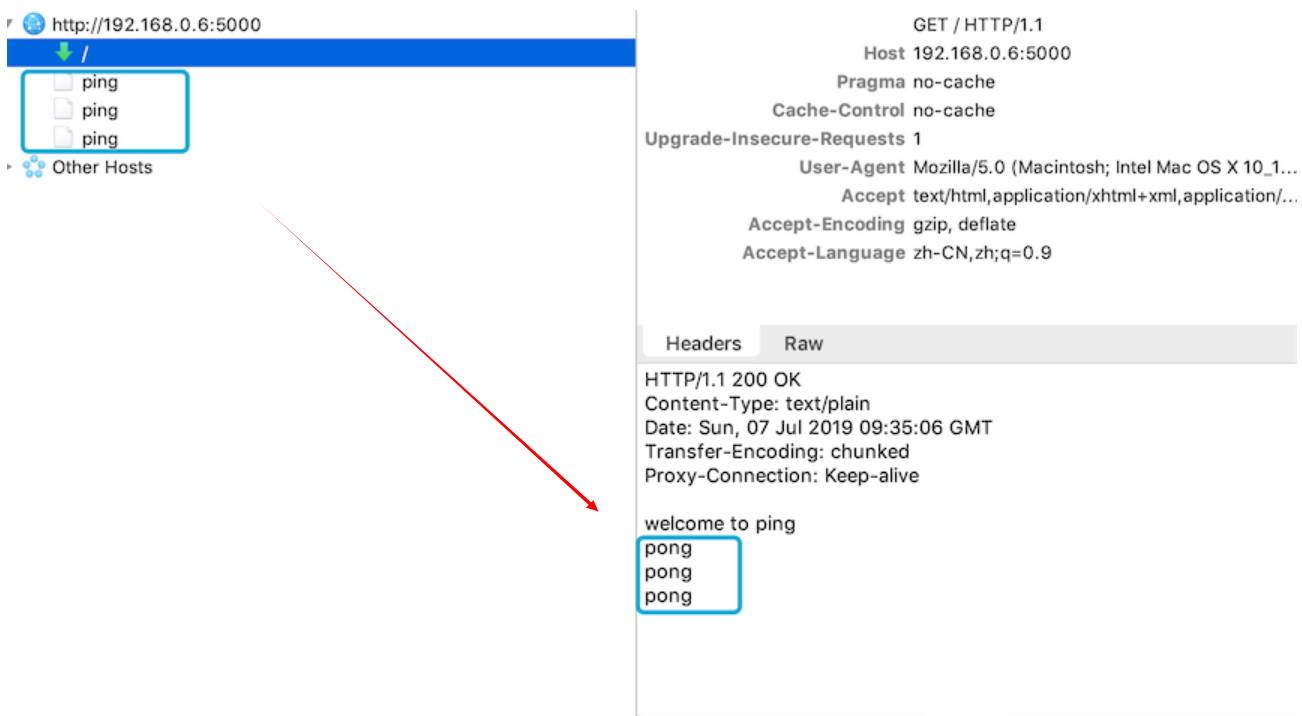
Ok! 这就是XHR-Streaming!
那么Ajax怎么接收这些数据呢? ①一种做法是在XMLHttpRequest的onreadystatechange事件处理器中判断readyState是否等于XMLHttpRequest.LOADING;②另外一种做法是在xhr.onprogress事件处理器中处理。下面是ping客户端实现:
function listen() {
const xhr = new XMLHttpRequest();
xhr.onprogress = () => {
// 注意responseText是获取服务端发送的所有数据,如果要获取未读数据,则需要进行划分
console.log('progress', xhr.responseText);
}
xhr.open('POST', HOST);
xhr.send(null);
}
function ping() {
const xhr = new XMLHttpRequest();
xhr.open('POST', HOST + '/ping');
xhr.send(null);
}
listen();
setInterval(ping, 5000);慢着,不要高兴得太早😰. 如果运行上面的代码会发现onprogress并没有被正常的触发, 具体原因笔者也没有深入研究,我发现sockjs的服务器源码里面会预先写入2049个字节,这样就可以正常触发onprogress事件了:
const server = http.createServer((req, res) => {
if (req.url === '/ping') {
// ping请求
// ...
} else {
// 保存句柄
res.writeHead(200, {
'Content-Type': 'text/plain',
});
res.write(Array(2049).join('h') + '\n');
pendingResponse = res
}
});最后再图解一下XHR-streaming的原理:
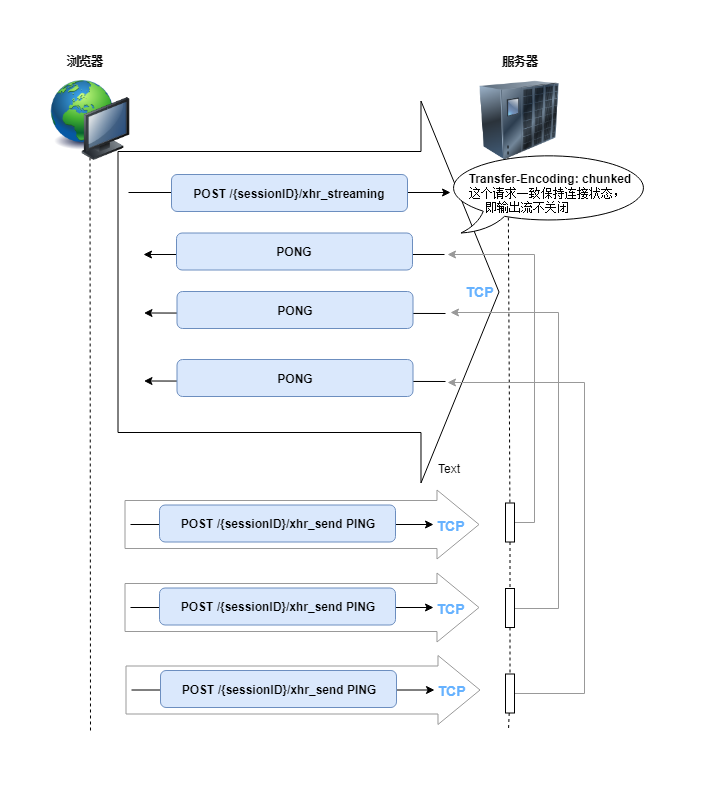
总结一下XHR-Streaming的特点:
- 利用分块传输编码机制实现持久化连接(persistent connection): 服务器不关闭响应流,连接就不会关闭
- 单工(unidirectional): 只允许服务器向浏览器单向的推送数据
通过XHR-Streaming,可以允许服务端连续地发送消息,无需每次响应后再去建立一个连接, 所以它是除了Websocket之外最为高效的实时通信方案. 但它也并不是完美无缺。
比如XHR-streaming连接的时间越长,浏览器会占用过多内存,而且在每一次新的数据到来时,需要对消息进行划分,剔除掉已经接收的数据. 因此sockjs对它进行了一点优化, 例如sockjs默认只允许每个xhr-streaming连接输出128kb数据,超过这个大小时会关闭输出流,让浏览器重新发起请求.
EventSource
了解了XHR-Streaming, 就会觉得EventSource并不是什么新鲜玩意: 它就是上面讲的XHR-streaming, 只不过浏览器给它提供了标准的API封装和协议, 你抓包一看和XHR-streaming没有太大的区别:
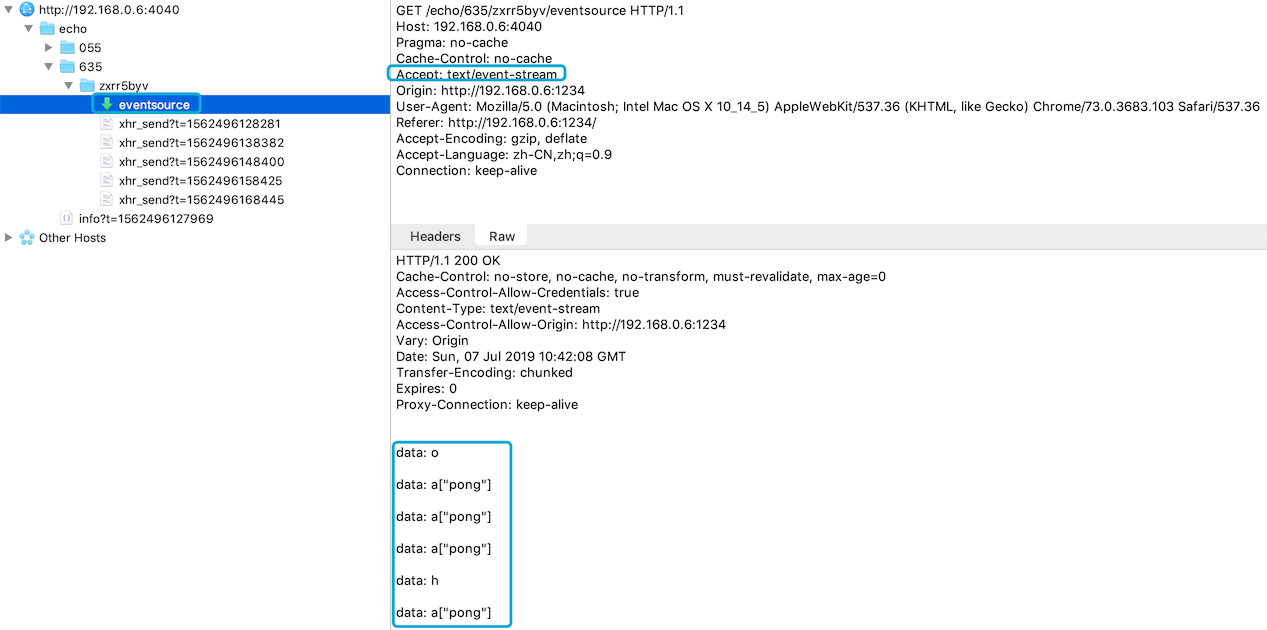
上面可以看到请求的Accept为text/event-stream, 且服务端写入的数据都有标准的约定, 即载荷需要这样组织:
const data = `data: ${payload}\r\n\r\n`EventSource的API和Websocket类似, 实例:
const evtSource = new EventSource('sse.php');
// 连接打开
evtSource.onopen = () => {}
// 接受消息
evtSource.onmessage = function(e) {
// do something
// ...
console.log("message: " + e.data)
// 关闭流
evtSource.close()
}
// 异常
evtSource.onerror = () => {}因为是标准的,浏览器调试也比较方便,不需要借助第三方抓包工具:
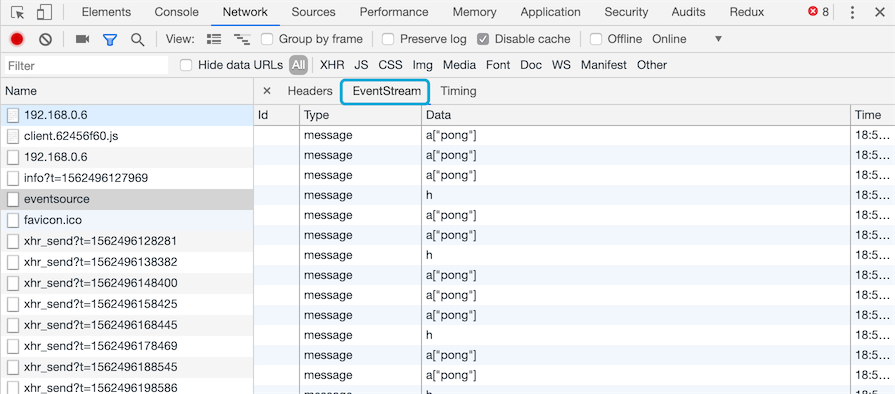
HtmlFile
这是一种古老的‘秘术’😂,虽然我们可能永远都不会再用到它,但是它的实现方式比较有意思(类似于JSONP这种黑科技), 所以还是值得讲一下。
HtmlFile的另一个名字叫做永久帧(forever-frame), 顾名思义, 浏览器会打开一个隐藏的iframe,这个iframe会请求一个分块传输编码的html文件(Transfer-Encoding: chunked), 和XHR-Streaming一样,这个请求永远都不会结束,服务器会不断在这个文档上输出内容。这里面的要点是现代浏览器都会增量渲染html文件,所以服务器可以通过添加script标签在客户端执行某些代码,先来看个抓包的实例:
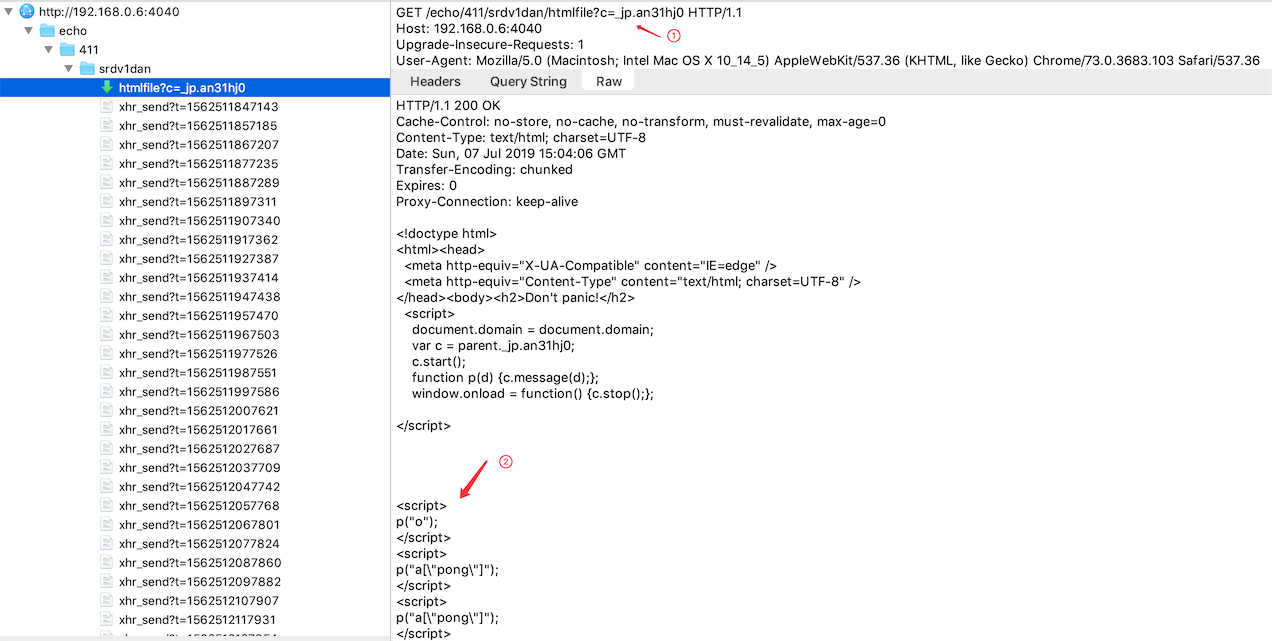
从上图可以看出:
- ① 这里会给服务器传递一个callback,通过这个callback将数据传递给父文档
- ② 服务器每当有新的数据,就向文档追加一个
<script>标签,script的代码就是将数据传递给callback。利用浏览器会被下载边解析HTML文档的特性,新增的script会马上被执行
最后还是用流程图描述一下:
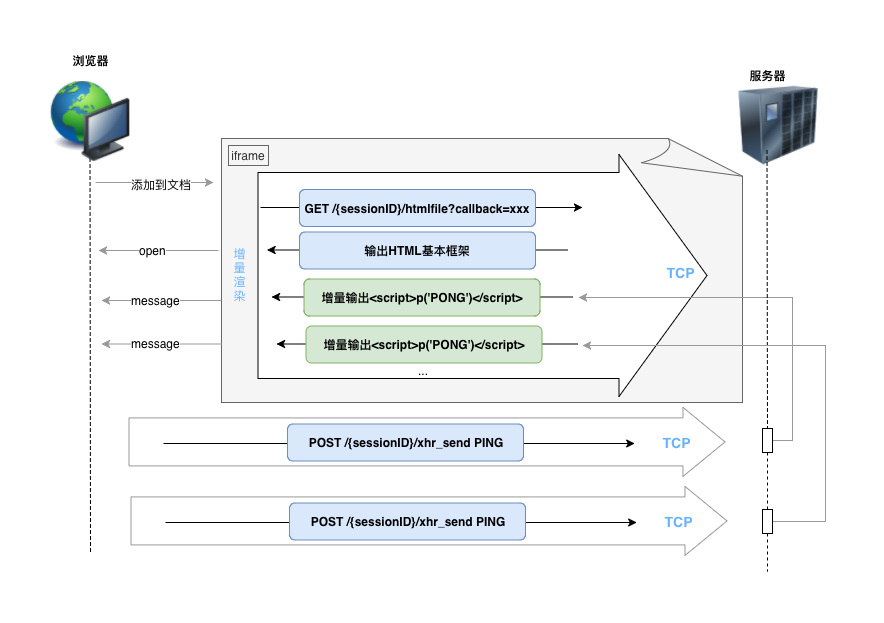
除了IE6、7以下不支持,大部分浏览器都支持这个方案,当浏览器不支持XHR-streaming时,可以作为最佳备胎。
Polling
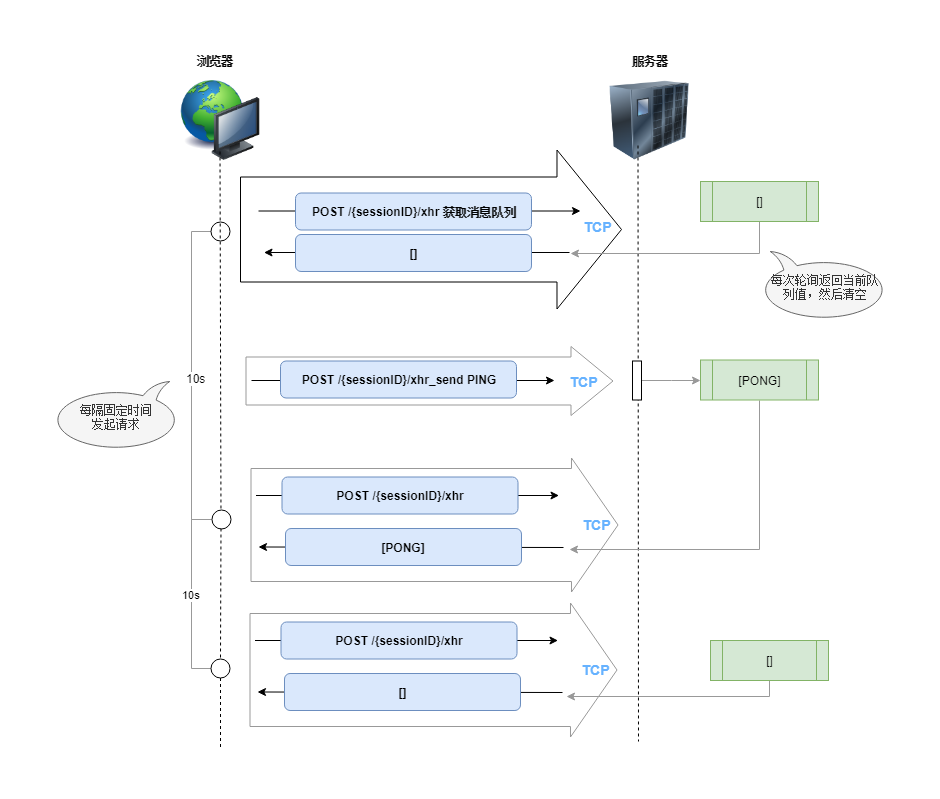
轮询是最粗暴(或者说最简单),也是效率最低下的‘实时’通信方案,这种方式的原理就是定期向服务器发起请求, 拉取最新的消息队列:
这种轮询方式比较合适服务器的信息定期更新的场景,如天气和股票行情信息。举个例子股票信息每隔5分钟更新一次,这时候客户端定期轮询, 且轮询间隔和服务端更新频率保持一致是一种理想的方式。
但是如果追求实时性,轮询会导致一些严重的问题:
- 资源浪费。比如轮询的间隔小于服务器信息更新的频率,这会浪费很多HTTP请求, 消耗宝贵的CPU时间和带宽
- 容易导致请求轰炸。比如当服务器负载比较高时,第一个请求还没处理完成,这时候第二、第三个请求接踵而来,无用的额外请求对服务端进行了轰炸。
Long polling
还有一种优化的轮询方法,称为长轮询(Long Polling),sockjs就是使用这种轮询方式, 长轮询指的是浏览器发送一个请求到服务器,服务器只有在有可用的新数据时才响应:
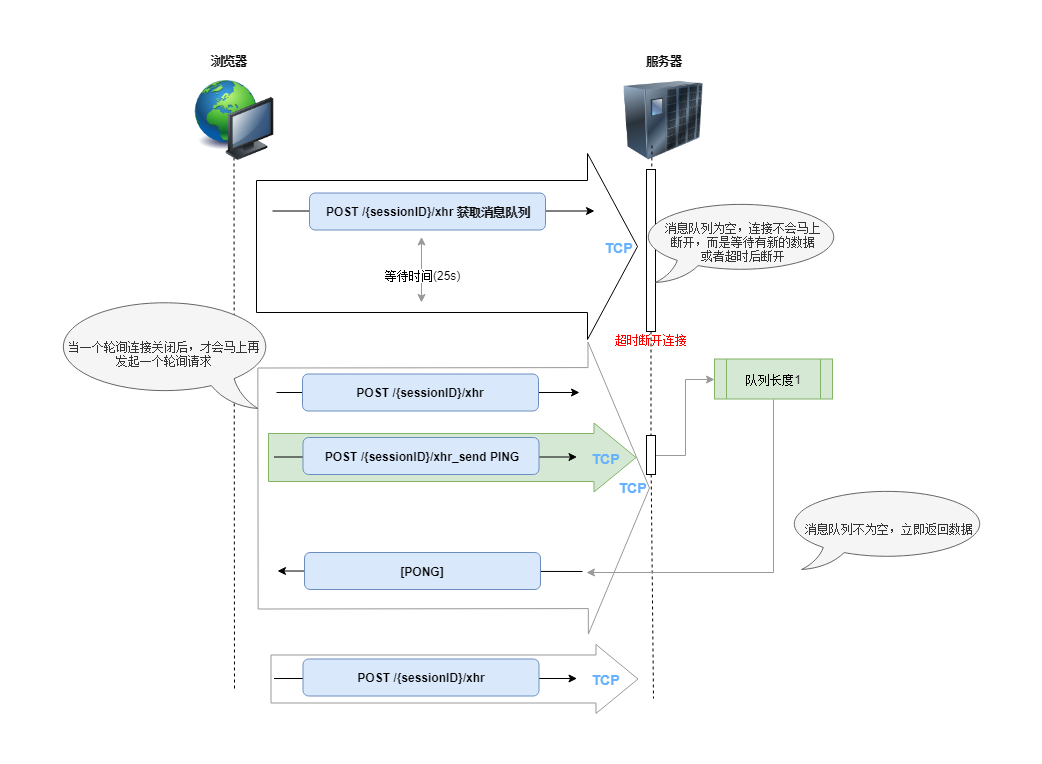
客户端向服务端发起一个消息获取请求,服务端会将当前的消息队列返回给客户端,然后关闭连接。当消息队列为空时,服务端不会立即关闭连接,而是等待指定的时间间隔,如果在这个时间间隔内没有新的消息,则由客户端主动超时关闭连接。
另外一个要点是,客户端的轮询请求只有在上一个请求连接关闭后才会重新发起。这就解决了上文的请求轰炸问题。服务端可以控制客户端的请求时序,因为在服务端未响应之前,客户端不会发送额外的请求(在超时期间内)。
扩展
- WebRTC 这是浏览器的实时通信技术,它允许网络应用或者站点,在不借助中间媒介的情况下,建立浏览器之间点对点(Peer-to-Peer)的连接,实现视频流和(或)音频流或者其他任意数据的传输。
- metetor DDP DDP(Distributed Data Protocol), 这是一个'有状态的'实时通信协议,这个是Meteor框架的基础, 它就是使用这个协议来进行客户端和服务端通信. 他只是一个协议,而不是通信技术,比如它的底层可以基于Websocket、XHR-Streaming、长轮询甚至是WebRTC
- 程序员怎么会不知道C10K 问题呢? - 池建强- Medium





**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。