
系统高可用的根基
随着公司业务不断的发展,系统也在变得越来越复杂。系统的复杂度体现在:前端对后端的依赖,后端服务之间的依赖。在没有明确强弱依赖的前提下,我们很难进行熔断、降级、限流的相关操作,也不能有效的对系统进行相关优化改造、持续推进系统稳定性提升。
强弱依赖的定义
在聊强弱依赖之前,我们先看下公司的服务分级标准:
S1 核心 S2次核心 S3 非核心 S4 其他
S1级别:影响业务线核心业务流程,会影响用户使用
S2级别:不涉及核心主业务流程,服务不可用会造成大范围用户体验下降。
S3级别:不涉及核心业务流程,应用不可用对用户几乎无影响,如头像、修改资料等一些长尾边缘应用。
S4级别:应用不可用对线上几乎无影响,如运营后台,如后台运营策略
在这里,我们对强弱依赖的定义即可得出:异常发生时,不影响核心业务流程,不影响系统可用性的依赖称作弱依赖,反之为强依赖。
强弱依赖治理
强弱依赖治理就是通过科学的手段持续稳定地得到应用间依赖关系、流量、强弱等数据,提前发现因为依赖问题可能导致的故障,避免依赖故障影响用户体验,积累数据持续推进系统稳定性提升。
两轮强弱依赖治理最佳实践
发现
人工梳理
在前期,我们通过投入相当人力,通过代码走读的形式将用车核心链路上的所有依赖进行梳理。
如何鉴定强弱依赖
先确定主业务,再评定依赖的服务对主业务有没有影响
eg:对于用户扫码业务,会有很多前置校验,比如用户用车资格、车辆信息和状态检查等。
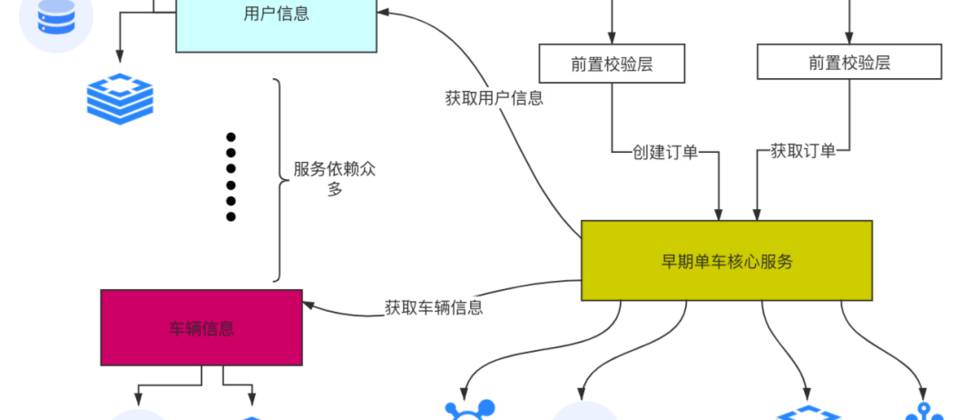
以的早期用车系统某服务为例(以下简称ride):

如上图所示,通过人工梳理发现,核心业务链路只有:创建订单/开始订单/结束订单/查询订单等,但服务依赖却有几十个,redis实例、数据库、mq等资源依赖也很多,究其原因,是因为ride服务一共提供了几十个接口,除了前面说到的4、5个接口是核心接口外,其他均为非核心接口,还有很多后置处理的业务逻辑,导致ride服务依赖很多核心流程不相关的弱依赖服务和资源,大大影响了服务的稳定性。
故障演练
后期,尤其故障演练在两轮的逐渐落地
我们通过服务配置文件整理服务依赖,然后通过故障演练,在线下逐个对依赖注入异常,验证主业务是否可用。从而鉴别强弱依赖。
目前我们正在运用故障演练,通过给两轮非S1核心服务注入异常,来识别核心链路的强弱依赖,防止核心链路上前、后端的劣化。这个点会在后续的文章《稳定性建设系列文章 -- 两轮故障演练最佳实践》详细展开,敬请期待。
改造&预案
前、后端容错改造
针对对核心业务有影响的场景和case,推动前后端去做容错改造。
1.前端:将非核心流程后端接口依赖解耦,异常情况下不阻塞核心流程
以确认开锁页为例,在确认开锁页,会去拉取各种区域需收取的调度费规则,以及骑行费用计价规则,最后会加载“确认开锁”按钮。

如果此页面对拉取这些计费规则的接口是强依赖,例如当后端聚合这些信息的接口出现故障时,将导致“确认开锁”按钮加载失败,业务流程无法推进,严重影响用户用车。
如果此页面对拉取这些计费规则的接口是弱依赖,例如当后端聚合这些信息的接口出现故障时,会导致部分计价规则信息内容加载不全,但核心业务流程仍可继续推进,用户体验并未受到太多影响。
故,前端需要将此类后端调用做好容错,进行解耦,将其变成弱依赖,使核心业务流程仍可继续推进。
2.后端:对弱依赖的异常做合理的捕获逻辑,配置合理的超时、熔断以及限流
设置合理的超时
从用户体验和系统稳定性角度出发,有关网络调用的请求,都需要配置超时。在服务端设置超时时,需要考虑到业务本身的执行耗时,加上序列化和网络通讯的时间。一般可按照接口RT的95或99线来设置超时间。当然客户端也可以根据自己的业务场景配置超时时间,例如一些前端应用,需要用户快速看到结果,可以把超时时间设置小一些。
设置熔断
某个服务故障或者异常时,如果该服务触发熔断,可以防止其他调用方一直等待超时或者故障,从而防止雪崩,只要是弱依赖服务,并且能设计合理的获取返回值的方案(返回值可以是默认值,或者通过一种后备(Fallback)方案获取的值),一般业务场景都可以做熔断处理。比如服务异常时我们可以熔断后走默认逻辑,让通过校验,既使核心业务流程仍可继续推进,也使得服务访问变低,给予了系统恢复的窗口。
设置限流
底层核心服务接口,以及核心对外的接口一定要做好限流,保证业务系统不会被大量突发请求击垮,提高系统稳定性。
核心与非核心业务隔离
线程级隔离
通过信号量或者线程池等技术实现线程隔离
进程级隔离
1.业务拆分
将非核心业务与核心业务进行服务拆分
2.分组部署
进行分组部署,让上游调核心和非核心调用访问不同的分组
下面以ride服务的治理为例,来说明在当时上线时间紧迫、稳定性要求高的背景下核心与非核心业务隔离这三种方式应如何做取舍。
首先,由于rpc请求调用的线程是由soa框架创建的,所以通过信号量或者线程池等技术实现线程隔离不可行;然后对于分组部署,因为当时的ride服务有多领域的业务逻辑,虽然分组部署能够解决运行时业务流量隔离的问题,但是没法避免因代码变更、发布引起的系统不稳定性。所以,我们最后选择了进行业务拆分,并且因为我们已经能够明确核心业务的范围以及核心业务上下游的依赖,影响范围可控,故最终我们决定将核心业务从服务中拆出,而不是将非核心业务拆出。如下图:

人工降级开关
针对具体的业务场景,以场景为最小单位,编写资损可控的业务兜底,配置相应的动态切换开关,异常发生时,可一键切换至兜底逻辑。
3.验证
我们通过服务配置文件服务依赖,然后通过故障演练,在线下逐个对依赖注入异常,验证主业务是否可用。从而鉴别和验证强弱依赖。
现状&问题
比较多关注服务与服务之间的依赖关系,忽略了对中间件(redis/hbase/mq等)的依赖。
比较多关注运行时阶段,忽略了对于启动阶段和停止阶段的治理。
(本文作者:周铭敏)

本文系哈啰技术团队出品,未经许可,不得进行商业性转载或者使用。非商业目的转载或使用本文内容,敬请注明“内容转载自哈啰技术团队”。






**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。