
上文,我们介绍了异地双活在哈啰四轮出行的落地。
本文主要讲述异地双活方案redis的热备、双写、双向同步的区别和优劣势。并且说明了双写同步方案中redis集群主从数据同步的过程,以及中间件方案遇到的部分问题点,说明最终方案的实现思路和方案。
redis的双活方案无非有以下三种:热备,双写,双向同步。下文会说明三个方案的区别,并着重讲解双向同步的方案。
热备
其中,热备由于备用redis集群平时不会被使用,只有双活故障切换才会使用,且该方案redis备机需要实时数据同步,则切换后的稳定性较低、并且需要同时维护两套集群,成本也不低。两个IDC同连一个redis集群,假如某个IDC距离过大,则必然至少有一个IDC和redis集群距离过大,则该方案的延迟相比原生redis会大大增加(该延迟同redis双写的延迟)。因此在异地双活中基本不会考虑,可做为前期的同城双活方案的过度方案,本文不会详细说明。
双写
双写,顾名思义就是两个机房同时写入,即在双活项目中,一个redis的命令写入本机房redis集群的同时,会同时写入另外一个机房的redis集群。保证两个机房redis数据是一致的。如下图所示:

在我理解中,双写主要分为以下四个方式:同步双写、异步双写、redis集群维度同步双写、redis集群维度异步双写。
同步双写
同步双写,指的是同个redis命令同时写入两个机房,是同步执行的。
例如:用户发了一个顺风车乘客订单,该订单被路由到中心机房(HZUNIT),且发单成功在业务上需要缓存订单数据到redis中,则该订单会先在中心机房(HZUNIT)写入一条缓存数据,同时会同步写入一条数据到异地的单元机房(SHUNIT)。
该方案存在以下几个问题:
- 维护成本
假如双写需要在业务代码层面维护,那代码侵入性会非常大。假如双写有个配置页面,配置需要双写的key,由中间件SDK实现双向,则每次新增或者修改双写的key都要去配置页面配置,后期维护中漏配风险非常大。
- 回滚问题
无论双写是在业务代码层面维护还是中间件SDK维护,那么当本机房操作成功,异地机房操作失败后,业务代码或者中间件代码需要考虑回滚逻辑,是跳过,还是回滚之前的命令,还是重试异地机房写入命令。如果选择重试,那一直失败如何处理,怎么保证数据一致性都是比较大的问题。
- 延迟
延迟是最致命的,众所周知redis的写入速度是非常高的,通常一个redis命令的写入是1ms以内,但是假如同步双写,则写入异地机房的时长会由两机房的物理距离决定,根据饿了么双活的测算,北京-上海的延迟大约为30ms,那这个异地的延迟是30倍,假设业务原先写入该redis命令的时间是1ms,那双写后变为31ms,显然这是无法接受的。
异步双写
异步双写,指的是同个redis命令写入两个机房,对本机房是同步写入的,对异地机房是异步写入的。
例如:用户发了一个顺风车乘客订单,该订单被路由到中心机房(HZUNIT),且发单成功在业务上需要缓存订单数据到redis中,则该订单会先在中心机房(HZUNIT)写入一条缓存数据,同时会异步写入一条数据到异地的单元机房(SHUNIT)。
该方案同样存在以下几个问题:
- 维护成本
与同步双写方案问题一致。
- 回滚问题
大部分与同步双写方案问题一致,且由于异步,一致性更无法保证。
- 延迟
该方案由于异地机房是异步写入,因此延迟问题影响几乎没有。(如数据要求强一致,则不适合用异步双写)
集群同步双写
集群同步双写,指的是同个redis命令写入两个机房,是同步执行的。但是双写是redis集群维度的,即配置了该redis集群为双写,那么整个redis集群的任意写入命令都会进行同步双写操作。
该方案同样存在以下几个问题:
- 维护成本
该方案的维护成本只在于新增redis集群后需要配置一下,或者通知中间件,维护成本较低。
- 回滚问题
与同步双写问题一致。
- 延迟
与同步双写问题一致。
集群异步双写
集群异步双写,指的是同个redis命令写入两个机房,对本机房是同步写入的,对异地机房是异步写入的。但是双写是redis集群维度的,即配置了该redis集群为双写,那么整个redis集群的任意写入命令都会进行异步双写操作。
该方案同样存在以下几个问题:
- 维护成本
该方案的维护成本只在于新增redis集群后需要新增配置一下,或者通知中间件,维护成本较低。
- 回滚问题
与异步双写问题一致。
- 延迟
与异步双写问题一致。
结论
从以上说明中可以看出redis集群维度同步双写相对于同步双写,有了较低的维护成本,延迟问题和回滚问题无法解决。redis集群维度异步双写相对于异步双写,有了较低的维护成本,回滚问题仍旧无法解决。无论同步双写还是redis集群维度同步双写延迟问题都是比较大的,因此这两个方案都最好不用。异步双写和redis集群维度异步双写,数据一致性问题则是一个大问题,因此该方案在某些数据一致性的场景下也不可用。基于以上两种方案,redis双向同步方案应运而生。
双向同步
参考:redis设计与实现
redis双向同步,即redis写入代码在业务侧无任何区别,还是只写入本机房,只是底层通过中间件同步任务,同步到异地机房。如下所示:

该方案也会有数据一致性问题,但是该方案的数据同步是中间件双向同步应用伪装为redis集群的slave节点,因此一致性的保证和redis集群的一致性保障是一致的,基本上能满足双活需求。
概念说明
复制偏移量(offset)
- 执行主从复制的双方都会分别维护一个复制偏移量
- master 每次向 slave 传播 N 个字节,自己的复制偏移量就增加 N
- slave 接收 N 个字节,自身的复制偏移量也增加 N。
- 通过对比主从之间的复制偏移量就可以知道主从间的同步状态
- offset会一直自增,不会到backlog的size停下从0开始
复制积压缓冲区(backlog)
- 为了解决断点重连全量同步问题设计
- master往slave同步数据时,会将数据往backlog也写一份
- 当master和slave网络抖动重新连接后,slave会将自己的offset发送给master
- master对比slave的offset和backlog的offset
- 如果slave的offset在backlog,则将复制缓冲区当前的offset之后的数据同步给slave
- 如果slave的offset不在backlog中,则进行全量同步
运行id(runid)
- 基于backlog逻辑缺陷设计
- 每个redis server无论主从都有自己的runid
- 由40位随机16进制字符组成。如:53b9b28df8042fdc9ab5e3fcbbbabff1d5dce2b3
- 如slave断网重连后,slave会将offset和当前保存的runid发送给master
- master对比slave传入的runid和自己的runid是否一致,从而判断是否同一个master
redis大版本解决问题
sync-->psync1-->psync2的进化
- redis2.8版本以下:无论是第一次主从复制还是断线重连后再进行复制都采用全量同步,因此如果redis主从节点网络抖动频繁,则会导致频繁的全量同比,导致整个集群压力较大。(同步方式sync)
- redis2.8-4.0以下版本:支持断点续传,但是master切换或者复制积压缓冲区满了以后,无法断点续传。(同步方式psync1)
- redis4.0及以上版本:支持master切换的断点续传,但是复制积压缓冲区满了也无法支持断点续传。(同步方式psync2)
sync
redis2.8版本以下,通过sync命令进行同步,集群无runid,backlog和offset,因此每次网络抖动导致的redis主从节点断开,等到主从节点重新连接后,都会进行全量的数据同步,现在该版本应该几乎没有在使用了,本文不做具体描述。
psync1
为了解决redis的断点续传而设计,通过runid和offset以及backlog,从而记录之前连接断开或者故障前的同步进度,等重新连接后根据offset和backlog断点续传。
无法解决问题:
- 断点后新写入的数据完全覆盖backlog,导致原先断开连接前的offset不在backlog中
- 主从切换后,由于主节点更换,也会引发全量同步
数据同步过程
数据全量同步过程如下所示:
- 当主从重新连接后,从服务器会告诉主服务器,是否是第一次执行,如果是的话,则向主服务器发送psync ? -1 命令,该命令代表从服务器告诉主服务器需要全量同步,则主服务器直接会把全量数据推给从服务器
- 如果从服务器告诉主服务器是断点续传,则会向主服务器发送psync 命令,告诉主服务器需要断点续传
- 当主服务判断offset不在backlog中,或者runid和自己id不一致,则会告诉从服务器需要进行全量同步,并把全量数据返回给从服务器
- 当主服务判断offset在backlog中,或者runid和自己id一致,则会进行断点续传
下图from:redis设计与实现

psync1命令的主从全量同步
当redis的主从关系是新的,会进行全量同步,或者之前执行过slaveof no one命令,全量同步的过程如下:
- slave从未任何master同步过数据(新的slave)或者是之前执行过slaveof no one命令,在开始新的一次复制之时向master发送psync?-1命令主动请求全量同步
- master执行bgsave,生成rdb文件,并发送数据到slave
- master返回+FULLRESYNC和master的runId以及当前的offset
- slave保存runId,并且将offset作为自己的初始化偏移量

psync1的增量同步(断点续传)
正常
- 正常情况下,redis主从同步是从主节点同步给从节点。(主节点发送的时候会带上runid和offset)
- 在同步过程中,master新写入的数据,会在backlog保存一份
异常
如因为网络原因导致连接异常,slave会自动请求master重新建立连接。
- slave发送connect
- slave发送psync runid offset
- 判断offset是否在backlog
- offset在backlog中:是的话会将backlog里面offset为slave offset之后的全部数据进行通报
- offset不在backlog中:进行全量同步

psync2解决的问题
- psync2主要是引入了replid(同runid)和replid2(之前的master的replid)
- slave的复杂积压缓冲区解决HA的全量同步问题
- slave的复制积压缓冲区作用,切换成master后,也有offset
- replid2的作用可以判断新的master和新的slave是否之前是一个集群,如果是一个集群则可以根据offset进行数据同步
- 主从切换的时候,根据replid2和offset进行增量同步
- 但是slave的offset大于当前backlog的最大offset,或者小于当前backlog的最小offset(不在backlog中)还是会进行全量同步
前面主要是说明redis本身集群的主从数据是如何同步的,而中间件的双向同步则是基于伪装未主从的slave进行的数据同步,后面则着重说明多主多从的情况下,数据是如何分配到正确的节点(卡槽)
卡槽判断逻辑
下图from:redis设计与实现

三主三从集群数据同步
以三主三从为例,数据分配节点和同步的过程如下:
- 客户端执行set k.v命令进行写入redis cluster(集群)
- 假如master1在集群初始化承接的slotid为0-5000,master2为5001-10000,master3位10001-16383
- redis cluster对key进行CRC16算法对16384取模,分别落入响应的master1或者master2或者master3
- 假如取模后的值为4500,则会写入master1,而master1会将该命令发送给slave1

中间件方案
伪装slave
伪装的slave节点交互与 master 的交互细节
- 发送 AUTH {password}
- 发送 REPLCONF listening-port {port} , 告知master自己的监听端口
- 发送 REPLCONF ip-address {address}, 告知master自己的ip
- 发送 REPLCONF capa eof (使用 diskless-replication)
- 发送 REPLCONF capa psync2
- 发送 PSYNC {repl_id} {repl_offset} , 发送复制id(master runid) 和自己复制进度offset
- 接收 Binary data
- 接收 aof data
双向同步方案
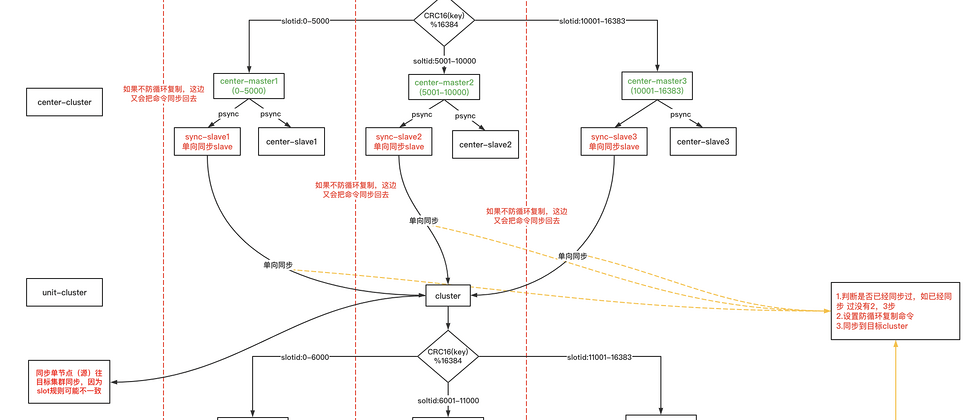
redis的双写同步方案是基于两个单元同步完成的,是一个单元到中心的单向同步和中心到单元的单向同步,两个合并为一个双写同步方案。
基本说明
- center_cluster代表中心机房的redis的集群
- center_master_node代表中心机房的redis的master节点
- unit_cluster代表单元机房的redis的集群
- unit_master_node代表单元机房的redis的master节点
- center_replication代表中间件中心到单元的同步任务
- unit_replication代表中间件单元到中心的同步任务
同步过程
以客户端写入在中心机房,同步到单元机房为例
- 客户端执行写入命令set k.v
- 该命令被分配到中心机房,center_cluster
- 该命令根据slotid分配到对应的master节点
- master节点会向中间件伪装成的slave节点发送数据,即向center_replication单向同步任务发送数据
- center_replication同步任务会同步到unit-cluster
- 后续则为unit-cluster单元机房redis集群自己的数据同步

问题--如何防循环复制
从同步过程可以看出,该双向同步是个环装,还是以上面例子为例,当center-master-node同步数据到unit-cluster后,unit-cluster也会有个unit-replication监听unit-master-node,进行同步到中心机房,则该命令会进行循环同步。
解法
通过固定前缀的防循环复制命令key,防止循环复制。
由于redis单线程的特性,在center-replation接收到主节点的命令后,会在set k,v命令后紧接跟着set一个固定前缀的key值(防循环复制key)。在unit-repliation接收到该节点的命令后,会getNext(),判断next命令是否防循环复制命令,如果是防循环复制key,则unit-repliation不会进行同步,否则的话,unit-repliation会进行同步。
问题:如何保证redis的原始命令的key和防循环复制的命令的slotid相同(不同则getNext会拿到非防循环命令,导致无法防循环复制)。
答:通过hashTag保证,具体可查询资料。
单向同步任务
单元同步任务是根据源和目标设置的,源即代表数据源的节点,该节点为单个master节点,目标即为目标的redis集群节点,为一个集群。即如果中心机房有三个主节点,则做中心到单元的单向同步,需要配置三个同步任务,每个同步任务的源节点为master1、master2、master3。目标节点均为正规单元机房redis集群。
问题:为何目标节点为redis集群?
因为单元和中心机房的主从数量不是一比一的,比如中心机房为三主三从,单元机房为2主2从。那么set k,v命令在中心机房属于master3,则在单元机房是属于master1或者master2。因此需要将目标数据同步到集群中,由集群的slot自行判断落入哪个master。
退一步说,即使中心机房为3主3从,单元机房也为3主3从,那么中心机房的master1不代表一定对应单元机房的master1,因为slotid的范围是和每个节点的性能也是相关的。
双向同步完整方案
以下是我自己画的redis双向同步完整方案,如下所示。

(本文作者:柳健强)

本文系哈啰技术团队出品,未经许可,不得进行商业性转载或者使用。非商业目的转载或使用本文内容,敬请注明“内容转载自哈啰技术团队”。






**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。