
概述:为提升系统稳定性,和线上故障的触达、定位、恢复的速度,以及建立一套可执行、便于操作的特色的演练规范,并沉淀通用、可移植的演练规范,故发起了故障演练。
故障演练的意义
混沌工程
介绍故障演练之前,先来了解一下混沌工程。Netflix在2012年发布了Chaos Monkey,向业界介绍了这个思想。引述一位业界先驱的话,混沌工程是一种深思熟虑的,经过计划来揭露系统弱点的实验。简单来说,就是将异常扰动注入已经呈现稳态的系统中,观测系统因此而产生的变化并作出对策,使今后系统面对同类异常扰动的变化delta在空间和时间维度上尽可能的小。
混沌工程不是一次性的实验,通过验证、改进和再实验,形成一种往复性的提升机制。根据混沌工程原则(PRINCIPLES OF CHAOS ENGINEERING),它在设计上强调了5大基本要素:
- 建立一个系统稳定状态运行的假设
首先我们需要一个稳定状态运行的系统,用于进行混沌实验。如何定义“稳定状态运行”,对于严谨科学的实验,我们不能从感观上去给“稳定状态运行”下定义,我需要给出具体的可测量的输出。关注系统这些可测量的输出,不去关心系统内部实现,在短时间内对这些输出的测量结果,就体现了“稳定状态运行”的程度。tps、rt、latency、错误率等指标,都可能成为体现稳态运行的感兴趣的指标。
- 多样化真实世界的事件
混沌实验中的变量反映了真实世界的时间。通过潜在影响和估计频率对事件优先级进行排序。认为与硬件故障(如服务器死机)、软件故障(如错误响应)和非故障事件(如流量激增或扩展事件)相对应的事件,任何能够破坏稳态运行的事件,都有可能成为混沌实验中的变量。
- 在生产环境中进行实验
系统的行为因环境和流量模式而异。由于可利用的行为随时可能发生变化,因此对真实流量进行采样是可靠捕获请求路径的唯一方法。为了保证系统运行方式的真实性以及与当前部署系统的相关性,Chaos 强烈建议直接在生产流量上进行实验。
- 持续自动化运行实验
手动运行实验是劳动密集型的,最终是不可持续的。自动化实验并持续运行。混沌工程将自动化构建到系统中以驱动编排和分析。
- 最小化爆炸半径
在生产中进行实验有可能给客户带来不必要的痛苦。虽然必须考虑到一些短期的负面影响,但混沌工程师有责任和义务确保实验产生的影响最小化并得到控制。
故障演练的意义

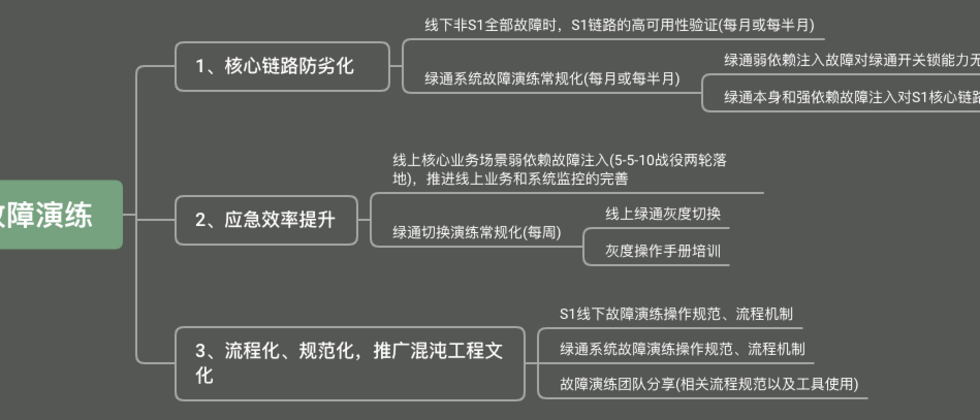
故障演练落地路径

核心链路防劣化
首先,我们的演练是从核心链路防劣化开始做起,防止日常迭代将核心链路和业务场景劣化掉。有几个前置工作:
- 前端核心action梳理。
- 核心业务场景梳理。
- 明确核心服务服务级别(S1)。
- 严格把控服务升入和降出核心服务服务级别(S1)。
按照前面所说的混沌工程5大基本要素,结合我的实验场景,我们按照以下4个步骤进行实验:
- 首先将“稳态”定义为指示系统正常运行的可测量指标
这里我们通过梳理一份核心链路回归case,用这份case做为系统“稳态”的可测量指标。
- 假设这种稳态将在对照组合实验组中持续下去
对照组:没有注入异常前的系统。实验组:注入异常后的系统。我们假设稳态的那一份case会在两组都持续正常下去。
- 引入反映现实世界事件的变量,如服务器崩溃、超时等
目前主要还只是做了宕机的事件引入,后续流程上和工具层面完善后,我们会继续加入类型超时、npe等真实事件进行实验。
- 试图通过寻找对照组和实验组的稳态上的差异,来反驳第2步中的假设
通过对对照组和实验组的case的结果的差异,来反驳第2步中的假设。反驳的难度越大,我们对系统行为的信心就越大。如果发现了一个弱点,我们就有了一个改进的目标,在该行为在生产上整个系统中表现出来之前。
由于做的是防止劣化的混沌实验,以及目前的基础设施水平,我们在5大基本要素上,并没有严格的执行,比如说:
我们没有在生产上进行实验,目前我们也没有做到自动化的程度(不过也是在积极落地为自动化case中)。具体详情如下:
- 建立一个系统稳定状态运行的假设
这边我们通过梳理一份核心链路回归case,通过case全部运行通过,来证明系统稳定状态运行的假设成立。
- 多样化的真实事件
目前主要还只是做了宕机的事件,后续流程上和工具层面完善后,我们会继续加入类型超时、npe等真实事件进行实验。
- 在生产环境中进行实验
因为目前的情况是需要对核心链路的劣化进行控制,故我们需要将所有的非核心服务注入异常,通过对爆炸半径的分析,故防劣化的实验在测试环境进行。
- 持续自动化实验
目前验证系统稳定状态运行的假设这一步还没有实现自动化(目前也是在积极落地为自动化case中),故我们目前是每个迭代人工持续的在进行防止劣化的实验,自动化这块目前还有很大的优化空间。
- 最小化爆炸半径
最小化半径这块,我们将爆炸半径控制在非S1服务,控制实验期间不影响其他业务线的正常测试,并达到我们自己的实验目的的效果。
应急效率提升
这一块主要是为了提升线上故障的应急效率5-5-10(监控告警的时效、故障原因定位的效率以及止血、故障恢复的快速性)而做的实验。所以我们严格按照混沌工程的5大要素进行实验。
首先我们选取了可以建立假设“稳态说”的可以测量的系统输出--业务核心(用车领域关键节点)大盘指标和注入的场景相关的tps、error指标;
其次在真实事件多样化这块,我们选取了目前超时异常和非超时异常(npe),来验证这两大类型的异常对系统稳态的影响;
第三,因为目标是应急,故我们的实验直接上到了生产进行;
第四,我们也是持续性、常规化的进行故障实验(自动化这一块,因为目前的进度、系统现状以及平台能力,暂时还不支持);
第五,最小化爆炸半径,从选取异常注入场景上,我们每次选择范围在3个左右,并且会在测试环境提前做影响范围验证;从故障注入工具层面,通过流量标识,保证异常注入期间异常只会影响压测流量,不影响上线真实流量;
混沌工程文化推广
S1线下故障演练操作规范、流程机制
绿通系统故障演练操作规范、流程机制
故障演练团队分享(相关流程规范以及工具使用)
演练流程的建议
因为故障演练本身是通过对照组和实验组的稳态结果进行对比而发现系统的弱点,故我们需要注意控制环境变量,提前做好check,保证两组之间的差异只由我们实验引入的真实事件而导致的。
实验结束后的环境验证。不管是线上环境还是线下环境,都有对应的使用用户,线上的为真实用车骑行用户,线下为我们的测试相关人员,我们不能因为故障演练去影响这些用户的正常使用。
(本文作者:周铭敏)
阅读哈啰技术更多干货合集

本文系哈啰技术团队出品,未经许可,不得进行商业性转载或者使用。非商业目的转载或使用本文内容,敬请注明“内容转载自哈啰技术团队”。






**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。