
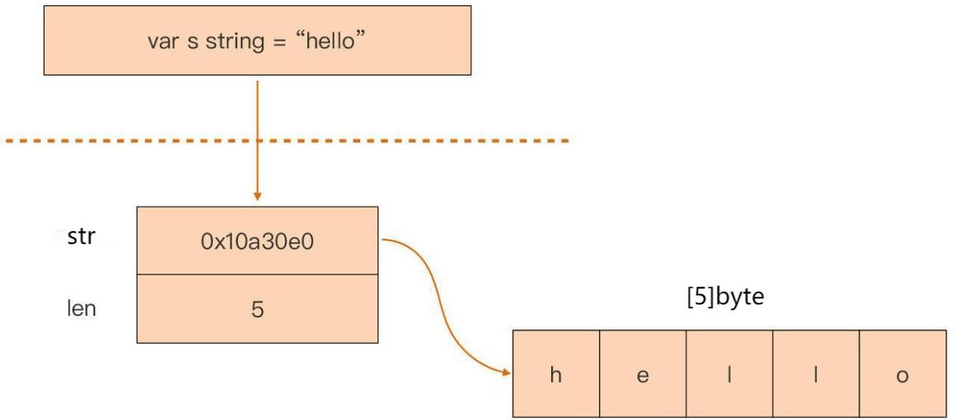
1. String structure definition
// src/runtime/string.go:stringStruct
type stringStruct struct {
str unsafe.Pointer
len int
}
The String type is actually a "descriptor" in the Go language memory model. It is represented by a 2-byte data structure. It does not actually store string data itself, but only a pointer to the underlying storage and the string. length field.
str : A pointer to the first address of the underlying storage of the string, 1 byte.
len : The length of the string, 1 byte.
Therefore, even if we directly use String type variables as function parameters, the overhead of passing them is constant and will not change with the size of the string.
2. String features
1. The value of type String is immutable during its lifetime
type stringStruct struct {
str unsafe.Pointer
len int
}
func main() {
var s string = "hello"
s[0] = 'a' //错误:无法给s[0]赋值,因为字符串内容是不可改变的
fmt.Printf("%#v\n", (*stringStruct)(unsafe.Pointer(&s)))
//输出:&main.stringStruct{str:(unsafe.Pointer)(0x2b599c), len:5}
s = "world" //修改字符串,字符串底层结构体中str指针已经发生变化
fmt.Printf("%#v\n", (*stringStruct)(unsafe.Pointer(&s)))
//输出:&main.stringStruct{str:(unsafe.Pointer)(0x2b5a00), len:5}
fmt.Printf("%#v\n", (*[5]byte)((*stringStruct)(unsafe.Pointer(&s)).str))
//输出:&[5]uint8{0x77, 0x6f, 0x72, 0x6c, 0x64} 分别对应 w o r l d 的 ASCII 码
}Since the runtime.stringStruct structure is non-exported and cannot be used directly, a stringStruct structure is manually defined.
The immutable characteristics of String type data improve the concurrency security and storage utilization of strings.
- Strings can be shared by multiple coroutines, and developers no longer have to worry about the concurrency safety of strings.
- For the same string value, no matter it is used in several places in the program, the compiler only needs to allocate a piece of storage for it, which greatly improves the storage utilization.
2. There is no trailing '\0', the length of the string is stored
There is no end '\0' in the Go string, and the length of the string is stored. The time complexity of obtaining the length of the string is constant. No matter how many characters there are in the string, we can quickly get the length value of the string.
3. String can be empty "" , but not nil
var s string = ""
s = nil // 错误4. Provide native support for non-ASCII characters, eliminating the possibility that the source code will display garbled characters in different environments
The Go language source file uses the Unicode character set by default. The Unicode character set is the most popular character set on the market. It includes almost all mainstream non-ASCII characters (including Chinese characters).
Every character in a Go string is a Unicode character, and these Unicode characters are stored in memory in UTF-8 encoding.
5. Natively supports "what you see is what you get" original strings, which greatly reduces the mental burden when constructing multi-line strings.
var s string = ` ,_---~~~~~----._
_,,_,*^____ _____*g*\"*,--,
/ __/ /' ^. / \ ^@q f
[ @f | @)) | | @)) l 0 _/
\/ \~____ / __ \_____/ \
| _l__l_ I
} [______] I
] | | | |
] ~ ~ |
| |
| |`
fmt.Println(s)3. String routine operations
1. Subscript operation
In the implementation of strings, it is the underlying array that actually stores the data. Subscripting a string is essentially equivalent to subscripting the underlying array. We actually encountered subscripting operations on strings in the previous code, in the form of:
var s = "乘风破浪"
fmt.Printf("0x%x\n", s[0]) // 0xe4:字符“乘” utf-8编码的第一个字节We can see that by subscripting, we get the byte at a specific subscript in the string, not the character.
2. Character iteration
Go has two forms of iteration: regular for iteration and for range iteration .
The results obtained by operating on strings through these two forms of iteration are different.
The operation of strings through regular for iteration is a byte-perspective iteration. The result of each iteration is a byte that constitutes the content of the string, and the subscript value where the byte is located , etc. Equivalent to iterating over the underlying array of strings:
var s = "乘风破浪"
for i := 0; i < len(s); i++ {
fmt.Printf("index: %d, value: 0x%x\n", i, s[i])
}output:
index: 0, value: 0xe4
index: 1, value: 0xb9
index: 2, value: 0x98 // "\xe4\xb9\x98" 乘
index: 3, value: 0xe9
index: 4, value: 0xa3
index: 5, value: 0x8e // "\xe9\xa3\x8e" 风
index: 6, value: 0xe7
index: 7, value: 0xa0
index: 8, value: 0xb4 // "\xe7\xa0\xb4" 破
index: 9, value: 0xe6
index: 10, value: 0xb5
index: 11, value: 0xaa // "\xe6\xb5\xaa" 浪Through for range iteration, each iteration we get is the code point value of the Unicode character in the string, and the offset value of the character in the string :
var s = "乘风破浪"
for i, v := range s {
fmt.Printf("index: %d, value: 0x%x\n", i, v)
}output:
index: 0, value: 0x4e58
index: 3, value: 0x98ce
index: 6, value: 0x7834
index: 9, value: 0x6d6a3. String concatenation
Although the development experience of string concatenation through +/+= is the best, the connection performance may not be the fastest.
Go also provides functions such as strings.Builder, strings.Join, fmt.Sprintf to perform string join operations.
4. String comparison
Go 字符串类型支持各种比较关系操作符,包括== 、 != 、 >= 、 <= 、 > < . In the comparison of strings, Go adopts the lexicographic comparison strategy, and starts to compare two string type variables byte by byte from the beginning of each string.
When the first different element appears between the two strings, the comparison ends, and the comparison result of these two elements will be used as the final comparison result of the strings. If two strings have different lengths, the string with the smaller length will be padded with empty elements, and empty elements are smaller than other non-empty elements.
If the lengths of the two strings are not the same, then we can conclude that the two strings are different without comparing the specific string data. However, if the two strings have the same length, it is necessary to further judge whether the data pointer points to the same underlying storage data. If it is still the same, then we can say that the two strings are equivalent. If they are different, we need to further compare the actual data content.
func main() {
// ==
s1 := "乘风破浪"
s2 := "乘风" + "破浪"
fmt.Println(s1 == s2) // true
// !=
s1 = "Go"
s2 = "PHP"
fmt.Println(s1 != s2) // true
// < and <=
s1 = "12345"
s2 = "23456"
fmt.Println(s1 < s2) // true
fmt.Println(s1 <= s2) // true
// > and >=
s1 = "12345"
s2 = "123"
fmt.Println(s1 > s2) // true
fmt.Println(s1 >= s2) // true
}Fifth operation: string conversion.
Go supports bidirectional conversion of strings and byte slices, strings and rune slices, and this conversion does not need to call any functions, just use explicit type conversions
var s = "乘风破浪"
// string -> []rune
rs := []rune(s)
fmt.Printf("%x\n", rs) // [4e58 98ce 7834 6d6a]
// string -> []byte
bs := []byte(s)
fmt.Printf("%x\n", bs) // e4b998e9a38ee7a0b4e6b5aa
// []rune -> string
s1 := string(rs)
fmt.Println(s1) // 乘风破浪
// []byte -> string
s2 := string(bs)
fmt.Println(s2) // 乘风破浪

**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。