
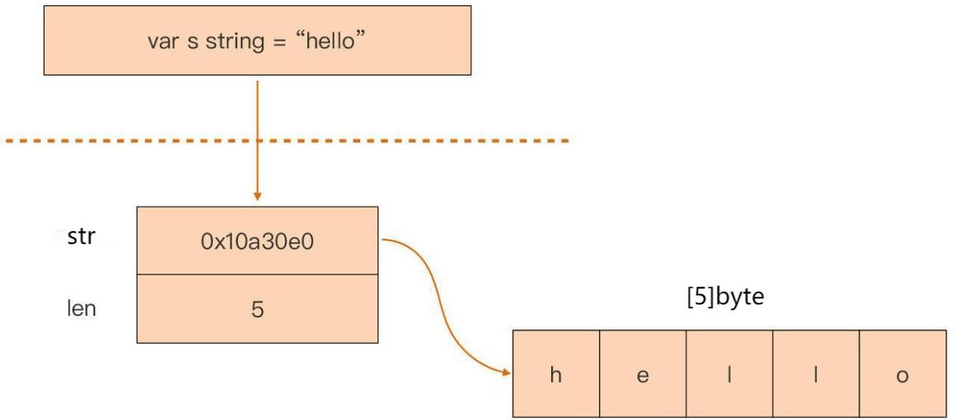
一、String 结构定义
// src/runtime/string.go:stringStruct
type stringStruct struct {
str unsafe.Pointer
len int
}
String 类型在Go语言内存模型中其实是一个“描述符”,用一个2字节的数据结构表示,它本身并不真正存储字符串数据,而仅是由一个指向底层存储的指针和字符串的长度字段组成的。
str:指向字符串底层存储首地址的指针,1字节。
len:字符串的长度,1字节。
因此,我们即便直接将 String 类型变量作为函数参数,其传递的开销也是恒定的,不会随着字符串大小的变化而变化。
二、String 特性
1. String 类型的值在它的生命周期内不可改变
type stringStruct struct {
str unsafe.Pointer
len int
}
func main() {
var s string = "hello"
s[0] = 'a' //错误:无法给s[0]赋值,因为字符串内容是不可改变的
fmt.Printf("%#v\n", (*stringStruct)(unsafe.Pointer(&s)))
//输出:&main.stringStruct{str:(unsafe.Pointer)(0x2b599c), len:5}
s = "world" //修改字符串,字符串底层结构体中str指针已经发生变化
fmt.Printf("%#v\n", (*stringStruct)(unsafe.Pointer(&s)))
//输出:&main.stringStruct{str:(unsafe.Pointer)(0x2b5a00), len:5}
fmt.Printf("%#v\n", (*[5]byte)((*stringStruct)(unsafe.Pointer(&s)).str))
//输出:&[5]uint8{0x77, 0x6f, 0x72, 0x6c, 0x64} 分别对应 w o r l d 的 ASCII 码
}由于runtime.stringStruct结构是非导出的,不能直接使用,所以手动定义了一个stringStruct结构体。
String 类型的数据不可改变的特性,提高了字符串的并发安全性和存储利用率。
- 字符串可以被多个协程共享,开发者不用再担心字符串的并发安全问题。
- 针对同一个字符串值,无论它在程序的几个位置被使用,编译器只需要为它分配一块存储,大大提高了存储利用率。
2. 没有结尾’\0’,存储了字符串长度
Go 字符串中没有结尾’\0’,并且存储了字符串长度,获取字符串长度的时间复杂度是常数,无论字符串中字符个数有多少,我们都可以快速得到字符串的长度值。
3. String 可以是空的"",但不能是 nil
var s string = ""
s = nil // 错误4. 对非 ASCII 字符提供原生支持,消除了源码在不同环境下显示乱码的可能
Go 语言源文件默认采用的是 Unicode 字符集,Unicode 字符集是目前市面上最流行的字符集,它囊括了几乎所有主流非 ASCII 字符(包括中文字符)。
Go 字符串中的每个字符都是一个 Unicode 字符,并且这些 Unicode 字符是以 UTF-8 编码格式存储在内存当中的。
5. 原生支持“所见即所得”的原始字符串,大大降低构造多行字符串时的心智负担。
var s string = ` ,_---~~~~~----._
_,,_,*^____ _____*g*\"*,--,
/ __/ /' ^. / \ ^@q f
[ @f | @)) | | @)) l 0 _/
\/ \~____ / __ \_____/ \
| _l__l_ I
} [______] I
] | | | |
] ~ ~ |
| |
| |`
fmt.Println(s)三、String 常规操作
1. 下标操作
在字符串的实现中,真正存储数据的是底层的数组。字符串的下标操作本质上等价于底层数组的下标操作。我们在前面的代码中实际碰到过针对字符串的下标操作,形式是这样的:
var s = "乘风破浪"
fmt.Printf("0x%x\n", s[0]) // 0xe4:字符“乘” utf-8编码的第一个字节我们可以看到,通过下标操作,我们获取的是字符串中特定下标上的字节,而不是字符。
2. 字符迭代
Go 有两种迭代形式:常规 for 迭代与 for range 迭代。
通过这两种形式的迭代对字符串进行操作得到的结果是不同的。
通过常规 for 迭代对字符串进行的操作是一种字节视角的迭代,每轮迭代得到的的结果都是组成字符串内容的一个字节,以及该字节所在的下标值,这也等价于对字符串底层数组的迭代:
var s = "乘风破浪"
for i := 0; i < len(s); i++ {
fmt.Printf("index: %d, value: 0x%x\n", i, s[i])
}输出:
index: 0, value: 0xe4
index: 1, value: 0xb9
index: 2, value: 0x98 // "\xe4\xb9\x98" 乘
index: 3, value: 0xe9
index: 4, value: 0xa3
index: 5, value: 0x8e // "\xe9\xa3\x8e" 风
index: 6, value: 0xe7
index: 7, value: 0xa0
index: 8, value: 0xb4 // "\xe7\xa0\xb4" 破
index: 9, value: 0xe6
index: 10, value: 0xb5
index: 11, value: 0xaa // "\xe6\xb5\xaa" 浪通过 for range 迭代,我们每轮迭代得到的是字符串中 Unicode 字符的码点值,以及该字符在字符串中的偏移值:
var s = "乘风破浪"
for i, v := range s {
fmt.Printf("index: %d, value: 0x%x\n", i, v)
}输出:
index: 0, value: 0x4e58
index: 3, value: 0x98ce
index: 6, value: 0x7834
index: 9, value: 0x6d6a3. 字符串连接
虽然通过 +/+= 进行字符串连接的开发体验是最好的,但连接性能就未必是最快的了。
Go 还提供了 strings.Builder、strings.Join、fmt.Sprintf 等函数来进行字符串连接操作。
4. 字符串比较
Go 字符串类型支持各种比较关系操作符,包括 ==、!= 、>=、<=、> 和 <。在字符串的比较上,Go 采用字典序的比较策略,分别从每个字符串的起始处,开始逐个字节地对两个字符串类型变量进行比较。
当两个字符串之间出现了第一个不相同的元素,比较就结束了,这两个元素的比较结果就会做为串最终的比较结果。如果出现两个字符串长度不同的情况,长度比较小的字符串会用空元素补齐,空元素比其他非空元素都小。
如果两个字符串的长度不相同,那么我们不需要比较具体字符串数据,也可以断定两个字符串是不同的。但是如果两个字符串长度相同,就要进一步判断,数据指针是否指向同一块底层存储数据。如果还相同,那么我们可以说两个字符串是等价的,如果不同,那就还需要进一步去比对实际的数据内容。
func main() {
// ==
s1 := "乘风破浪"
s2 := "乘风" + "破浪"
fmt.Println(s1 == s2) // true
// !=
s1 = "Go"
s2 = "PHP"
fmt.Println(s1 != s2) // true
// < and <=
s1 = "12345"
s2 = "23456"
fmt.Println(s1 < s2) // true
fmt.Println(s1 <= s2) // true
// > and >=
s1 = "12345"
s2 = "123"
fmt.Println(s1 > s2) // true
fmt.Println(s1 >= s2) // true
}5. 字符串转换。
Go 支持字符串与字节切片、字符串与 rune 切片的双向转换,并且这种转换无需调用任何函数,只需使用显式类型转换就可以了
var s = "乘风破浪"
// string -> []rune
rs := []rune(s)
fmt.Printf("%x\n", rs) // [4e58 98ce 7834 6d6a]
// string -> []byte
bs := []byte(s)
fmt.Printf("%x\n", bs) // e4b998e9a38ee7a0b4e6b5aa
// []rune -> string
s1 := string(rs)
fmt.Println(s1) // 乘风破浪
// []byte -> string
s2 := string(bs)
fmt.Println(s2) // 乘风破浪

**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。