
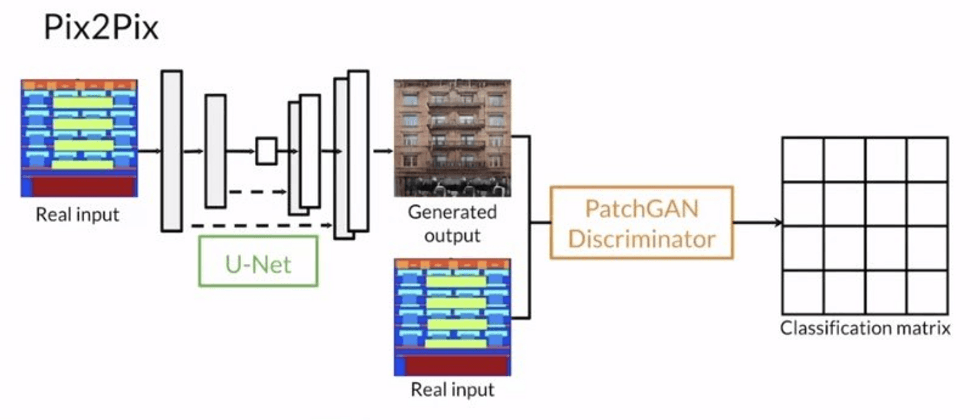
对比两个框架实现同一个模型到底有什么区别?
第一步,我们对数据集进行图像预处理。我们在这里选择 Facades 数据集,我们将 2 张图像合并为一张,以便在训练过程中进行一些增强。

Pytorch:
def __getitem__(self, index):img = Image.open(self.files[index % len(self.files)])
w, h = img.size
img_A = img.crop((0, 0, w / 2, h))
img_B = img.crop((w / 2, 0, w, h))if np.random.random() < 0.5:
img_A = Image.fromarray(np.array(img_A)[:, ::-1, :], "RGB")
img_B = Image.fromarray(np.array(img_B)[:, ::-1, :], "RGB")img_A = self.transform(img_A)
img_B = self.transform(img_B)return {"A": img_A, "B": img_B}Keras:
def load_batch(self, batch_size=1, is_testing=False):
data_type = "train" if not is_testing else "val"
path = glob('./datasets/%s/%s/*' % (self.dataset_name, data_type))self.n_batches = int(len(path) / batch_size)for i in range(self.n_batches-1):
batch = path[i*batch_size:(i+1)*batch_size]
imgs_A, imgs_B = [], []
for img in batch:
img = self.imread(img)
h, w, _ = img.shape
half_w = int(w/2)
img_A = img[:, :half_w, :]
img_B = img[:, half_w:, :]img_A = resize(img_A, self.img_res)
img_B = resize(img_B, self.img_res)if not is_testing and np.random.random() > 0.5:
img_A = np.fliplr(img_A)
img_B = np.fliplr(img_B)imgs_A.append(img_A)
imgs_B.append(img_B)imgs_A = np.array(imgs_A)/127.5 - 1.
imgs_B = np.array(imgs_B)/127.5 - 1.yield imgs_A, imgs_B模型
在论文中提到使用的模型是 U-Net,所以需要使用层间的跳跃连接(恒等函数)。使用上采样和下采样卷积制作自编码器生成和判别模型。


Pytorch:
class Generator(nn.Module):
def __init__(self, in_channels=3, out_channels=3):
super(Generator, self).__init__()
self.down1 = DownSampleConv(in_channels, 64, batchnorm=False)
self.down2 = DownSampleConv(64, 128)
self.down3 = DownSampleConv(128, 256)
self.down4 = DownSampleConv(256, 512, dropout_rate=0.5)
self.down5 = DownSampleConv(512, 512, dropout_rate=0.5)
self.down6 = DownSampleConv(512, 512, dropout_rate=0.5)
self.down7 = DownSampleConv(512, 512, dropout_rate=0.5)
self.down8 = DownSampleConv(512, 512, batchnorm=False, dropout_rate=0.5)self.up1 = UpSampleConv(512, 512, dropout_rate=0.5)
self.up2 = UpSampleConv(1024, 512, dropout_rate=0.5)
self.up3 = UpSampleConv(1024, 512, dropout_rate=0.5)
self.up4 = UpSampleConv(1024, 512, dropout_rate=0.5)
self.up5 = UpSampleConv(1024, 256)
self.up6 = UpSampleConv(512, 128)
self.up7 = UpSampleConv(256, 64)self.last_conv = nn.Sequential(
nn.Upsample(scale_factor=2),
nn.ZeroPad2d((1, 0, 1, 0)),
nn.Conv2d(128, out_channels, 4, padding=1),
nn.Tanh(),
)def forward(self, x):
ds1 = self.down1(x)
ds2 = self.down2(ds1)
ds3 = self.down3(ds2)
ds4 = self.down4(ds3)
ds5 = self.down5(ds4)
ds6 = self.down6(ds5)
ds7 = self.down7(ds6)
ds8 = self.down8(ds7)
us1 = self.up1(ds8, ds7)
us2 = self.up2(us1, ds6)
us3 = self.up3(us2, ds5)
us4 = self.up4(us3, ds4)
us5 = self.up5(us4, ds3)
us6 = self.up6(us5, ds2)
us7 = self.up7(us6, ds1)
return self.last_conv(us7)class Discriminator(nn.Module):
def __init__(self, in_channels=3):
super(Discriminator, self).__init__()self.model = nn.Sequential(
DownSampleConv(in_channels + in_channels, 64, batchnorm=False, inplace=True),
DownSampleConv(64, 128, inplace=True),
DownSampleConv(128, 256, inplace=True),
DownSampleConv(256, 512, inplace=True),
nn.ZeroPad2d((1, 0, 1, 0)),
nn.Conv2d(512, 1, (4, 4), padding=1, bias=False)
)def forward(self, x, y):
img_input = torch.cat([x, y], 1)
return self.model(img_input)Keras
def build_generator(self):
initializers = RandomNormal(stddev=0.02)
input_image = Input(shape=self.img_shape)
e1 = self.encoder_block(input_image, 64, batchnorm=False)
e2 = self.encoder_block(e1, 128)
e3 = self.encoder_block(e2, 256)
e4 = self.encoder_block(e3, 512)
e5 = self.encoder_block(e4, 512)
e6 = self.encoder_block(e5, 512)
e7 = self.encoder_block(e6, 512)d2 = self.decoder_block(e7, e6, 512)
d3 = self.decoder_block(d2, e5, 512)
d4 = self.decoder_block(d3, e4, 512)
d5 = self.decoder_block(d4, e3, 256)
d6 = self.decoder_block(d5, e2, 128)
d7 = self.decoder_block(d6, e1, 64)
up = UpSampling2D(size=2)(d7)
output_image = Conv2D(self.channels, (4, 4), strides=1, padding='same', kernel_initializer=initializers,
activation='tanh')(up)
model = Model(input_image, output_image)
return modeldef build_discriminator(self):
initializers = RandomNormal(stddev=0.02)
input_source_image = Input(self.img_shape)
input_target_image = Input(self.img_shape)
merged_input = Concatenate(axis=-1)([input_source_image, input_target_image])
filters_list = [64, 128, 256, 512]def disc_layer(input_layer, filters, kernel_size=(4, 4), batchnorm=True):
x = Conv2D(filters, kernel_size=kernel_size, strides=2, padding='same', kernel_initializer=initializers)(
input_layer)
x = LeakyReLU(0.2)(x)
if batchnorm:
x = BatchNormalization()(x)
return xx = disc_layer(merged_input, filters_list[0], batchnorm=False)
x = disc_layer(x, filters_list[1])
x = disc_layer(x, filters_list[2])
x = disc_layer(x, filters_list[3])discriminator_output = Conv2D(1, kernel_size=(4, 4), padding='same', kernel_initializer=initializers)(x)
model = Model([input_source_image, input_target_image], discriminator_output)
return model训练过程
对于训练,我们继续使用生成器和鉴别器架构。使用论文中建议的权重初始化方法更改权重初始化器(权重从均值为 0 的高斯分布初始化, 标准差 0.02)。此外还有一些训练的超参数。(Adam优化器,LR=0.0002, B1=0.5, B2=0.999)

Pytorch:
# Training
prev_time = time.time()
for epoch in range(init_epoch, n_epochs):
for i, batch in enumerate(dataloader):real_A = Variable(batch["B"].type(Tensor))
real_B = Variable(batch["A"].type(Tensor))valid = Variable(Tensor(np.ones((real_A.size(0), *patch))), requires_grad=False)
fake = Variable(Tensor(np.zeros((real_A.size(0), *patch))), requires_grad=False)# Train Generators
optimizer_G.zero_grad()# GAN loss
fake_B = generator(real_A)
pred_fake = discriminator(fake_B, real_A)
loss_GAN = criterion_GAN(pred_fake, valid)
loss_pixel = criterion_pixelwise(fake_B, real_B)
loss_G = loss_GAN + lambda_pixel * loss_pixel
loss_G.backward()
optimizer_G.step()# Train Discriminator
optimizer_D.zero_grad()
pred_real = discriminator(real_B, real_A)
loss_real = criterion_GAN(pred_real, valid)
pred_fake = discriminator(fake_B.detach(), real_A)
loss_fake = criterion_GAN(pred_fake, fake)
loss_D = (loss_real + loss_fake) * 0.5
loss_D.backward()
optimizer_D.step()batches_done = epoch * len(dataloader) + i
batches_left = n_epochs * len(dataloader) - batches_done
time_left = datetime.timedelta(seconds=batches_left * (time.time() - prev_time))
prev_time = time.time()# Print log
sys.stdout.write(
"\r[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f, pixel: %f, adv: %f] ETA: %s"
% (epoch, n_epochs, i, len(dataloader), loss_D.item(), loss_G.item(), loss_pixel.item(),
loss_GAN.item(), time_left)
)
G_losses.append(loss_G.item())
D_losses.append(loss_D.item())Keras:
def train(self, epochs, batch_size=1, sample_interval=50):
valid = np.ones((batch_size,) + self.disc_patch)
fake = np.zeros((batch_size,) + self.disc_patch)for epoch in range(epochs):
for batch_i, (imgs_A, imgs_B) in enumerate(self.data_loader.load_batch(batch_size)):fake_A = self.generator.predict(imgs_B)d_loss_real = self.discriminator.train_on_batch([imgs_A, imgs_B], valid)
d_loss_fake = self.discriminator.train_on_batch([fake_A, imgs_B], fake)
d_loss = 0.5 * np.add(d_loss_real, d_loss_fake)g_loss = self.combined.train_on_batch([imgs_A, imgs_B], [valid, imgs_A])print(
"[Epoch %d/%d] [Batch %d/%d] [D loss: %f,D Loss Real: %f, D Loss Fake: %f, acc: %3d%%] [G loss: %f, L1 Loss: %f, acc: %3d%%]" % (
epoch, epochs,
batch_i, self.data_loader.n_batches,
d_loss[0], d_loss_real[0], d_loss_fake[0], 100 * d_loss[1],
g_loss[0], g_loss[1], 100 * g_loss[2]))
self.G_losses.append(g_loss[0])
self.D_losses.append(d_loss[0])
if batch_i % sample_interval == 0:
self.sample_images(epoch, batch_i)
self.plot_metrics(self.G_losses, self.D_losses)这样我们就实现了一个完整的流程,可以看到,除了训练这块其他步骤两个框架的差别基本不大。如果你对完整代码感兴趣,本文代码如下:
https://avoid.overfit.cn/post/be317cf0a41c4a48b8a80398489120b3
作者:vargha khallokhi




**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。