
你是否遇到过数据集中有多个文本特性的情况?例如,根据消息的上下文正确地对消息进行分类,即理解前面的消息。比如说我们有下面的数据集,需要对其进行分类。

当只考虑message时,你可以看到它的情绪是积极的,因为“incredible”这个词。但是当考虑到背景时,我们可以看到它时消极的
所以对于上下文来说,我们需要知道更多的信息,例如:
- 是否值得将上下文作为一个单独的特征来考虑?
- 将两个文本特征集中在一起是否会提高模型的性能?
- 是否应该引入上下文和信息的权衡?如果是,合适的权重比例是多少?
本文有一个简单的实现,就是:将两个文本字段连接起来。与仅使用最新消息相比,它能给模型带来改进——但是我们应该深入研究两个文本的权重比例。所以可以创建一个神经网络,它有两种模式,每个模式上的密集层大小可调?这样,我们就能自动找到合适的权重!
这里我们介绍的TwoModalBERT支持在nn中查找两个文本模式的适当权重比例!让我们看看里面的神经网络是如何构建的。
TwoModalBERT体系结构
下面可以看到TwoModalBERT是如何构造的以及类参数
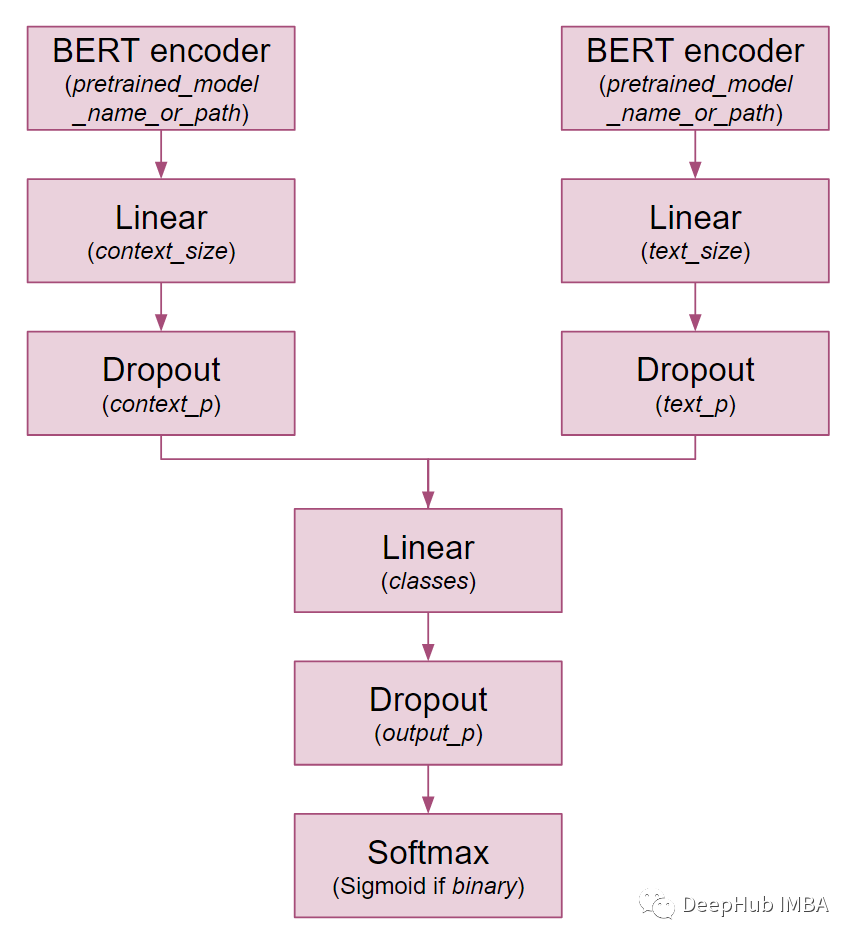
首先,在最后一个BERT层之上添加一个线性层。我们还是沿用BERT的配置,将其应用在CLS令牌之上。由于CLS令牌聚合了整个序列表示,它经常用于分类任务中。为了更好地理解,让我们看看相关的三行代码。
outputs = self.model(input_ids=input_ids, attention_mask=attention_mask)
last_hidden_states = outputs['hidden_states'][-1]
# last layer size: (batch_size, seq_len, hs)
cls_hidden_states = last_hidden_states[:, 0, :]
last_hidden_states_reduced = linear_layer(cls_hidden_states)线性层将隐藏大小与BERT模型相关的输入特征转换为隐藏大小等于预定义的context_size和text_size的特征,对于transformer包中可用的模型,隐藏层大小通常为768。
然后添加一个dropout层使神经网络对神经元的具体权重不那么敏感,不容易过拟合。
最后,将两个类似创建的分支组合在一起,后面跟着另一个dropout层。
TwoModalBERT包
TwoModalBERT包允许我们用上面描述的双模态神经网络体系结构快速运行实验。它允许在Pytorch和transformer库之上快速构建模型,并允许对两个输入文本的权重进行实验。
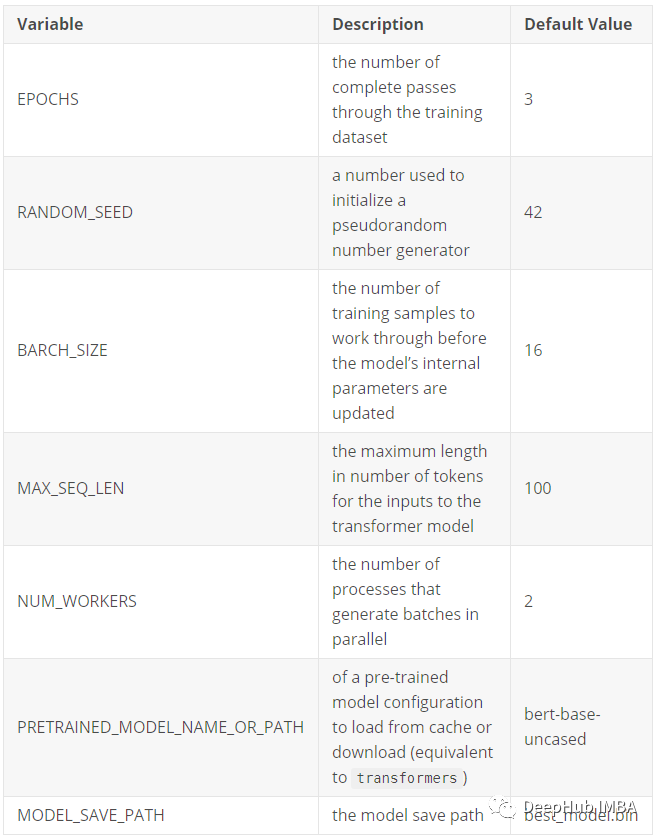
我们应该使用下表中描述的参数创建config.ini文件。
在设置了初始参数之后,我们可以查看这个示例。这里将使用包含该系列所有对话的“The Office”数据集(https://www.kaggle.com/datase...)。我们的目标是验证:根据前一行和当前行对比仅当前行的文本来识别说话的角色是否具有更高的准确率。
我们对数据集进行简单的预处理后,数据集如下所示:
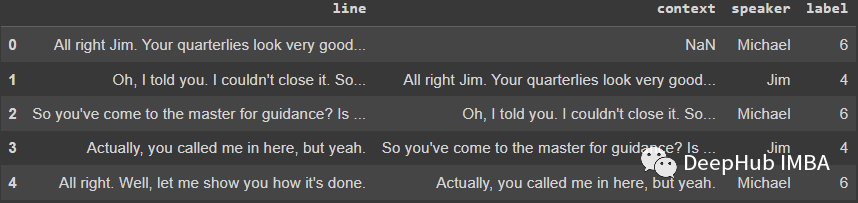
这里的三个列是
- line 说话人说的话
- context 前一位说话人所说的内容
- label 与每个演讲者相关的数字
# intialize modules
DataPreparation = TwoModalDataPreparation(config=config)
Trainer = TwoModalBertTrainer(device=DEVICE, config=config)
# create data loaders
(
train_data_loader,
train,
val_data_loader,
val,
test_data_loader,
test,
) = DataPreparation.prepare_data(
df,
text_column="line",
context_column="context",
label_column="label",
train_size=0.8,
val_size=0.1,)在创建数据加载器之后,就可以训练模型了。这里使用的所有神经网络参数都在前面的列表中给出了。我们设置text_size = 100和context_size = 1。
# train the model
model, history = Trainer.train_model(
train_data_loader,
train,
val_data_loader,
val,
text_size=100,
context_size=50,
binary=False,
text_p=0.3,
context_p=0.3,
output_p=0.3,
)
# evaluate the model on a test set
y_pred, y_test = test_model(model, test_data_loader)
y_pred, y_test = [e.cpu() for e in y_pred], [e.cpu() for e in y_test]由于模型经过了训练,我们可以在测试集上对其进行评估(可以在y_pred和y_test上应用任何度量)。下面我们查看混淆矩阵。
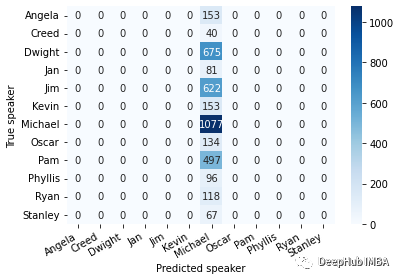
除了Michael,模特没有学会识别任何角色。我们把context_size增加到50,看看混淆矩阵如何变化?
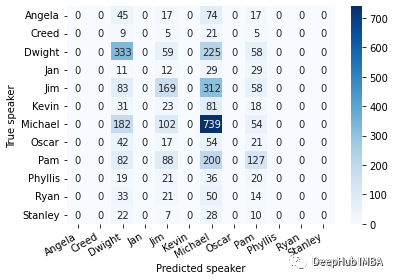
可以观察到,模型学会了识别 Dwight, Michael, Jim。对于一些其他角色来说,这种方法并不适用。但是与前一个选项相比,有很大的改进,并且通过配置context_size我们还有更多的提升空间
然后我们看看模型如何做推理:
# run on new pair of text inputs
line = "Dwight is my best friend."
context = "What do you think about Dwight?"
predict_on_text(model, line, context)模型可以返回正确的结果:Stanley
总结
本文介绍的TwoModalBERT包的可以说是一个非常简单的魔改模型,它不需要对模型内部进行修改,只需要修改外部的梳理过就就可以快速提高两个输入文本字段的不同加权模式对分类神经网络性能的影响。本文的完整代码请见:https://avoid.overfit.cn/post...
作者:Zuzanna Deutschman







**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。