
工作中用过一段时间的Kafka,不过主要还是RabbitMQ用的多一些。今天主要来讲讲与RabbitMQ相关的一些知识。一些基本概念,以及实际使用场景及一些注意事项。
1 基本概念
RabbitMQ使用Erlang开发,实现了高级消息队列协议(AMQP),同时还支持MQTT、STOMP等。

1.1 核心概念
- Broker: 消息队列服务主机
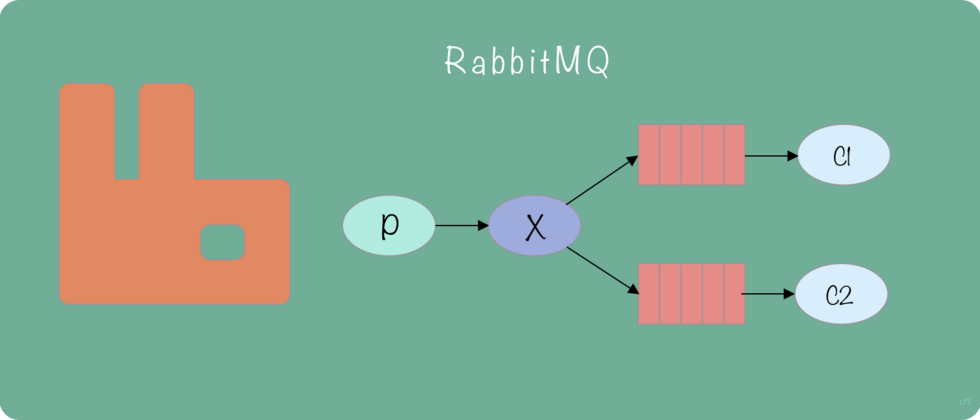
- Exchange: 消息交换机,可按照特定规则将消息路由到具体队列 (上图
X即为交换机) - Queue: 消息队列,每个消息理论都要被投入到一个或多个队列 (上图红色矩形即为队列)
- Binding: 绑定关系,将
Exchange和Queue按照某个路由规则进行绑定 - RoutingKey: 路由关键字,
Exchange根据该Key进行不同的路由 - Vhost: 虚拟主机,在同一物理主机上做资源逻辑隔离,类似
命名空间? - Connection: 客户端与主机建立的TCP连接
- Channel: 消息通道,同一
Connection可以有多个Channel,每个Channel都有一个唯一ID
1.2 交换机
按类型分四种:Direct Exchange,Topic Exchage,Fanout Exchange,Headers Exchange
1.2.1 Direct Exchange
直接交换机,在没复杂路由场景时,这种路由器使用的较多。特点是严格RoutingKey路由。只有当RoutingKey完全一致时,才会今天路由投递。

1.2.2 Fanout Exchange
广播交换机,一个消息需要无差别投递到所有绑定的队列中时。无需设置RoutingKey,即使设置了也不会生效。

1.2.3 Topic Exchange
主题交换机,类似直接交换机。不同的是可以根据RoutingKey进行模糊匹配(#表示一个或多个单词,*表示一个单词)。
这样来看的话。
- 当不使用
#或*进行模糊匹配时,它跟Direct Exchange似乎没啥区别。 - 当仅使用
#进行模糊匹配时,它跟Fanout Exchange似乎也没啥区别。

可以看到:
Q1可以匹配:x11.orange.x22,但无法匹配x00.x11.orange.x22。Q2可以匹配:lazy.orange,也能匹配lazy.orange.rabbit。
1.2.4 Headers Exchange
请求头交换机,不使用RoutingKey路由,根据消息头中的key-value属性进行路由。

可以通过设置x-match: any、x-match: all来进行or、and逻辑匹配。
1.2.5 其他属性
- Durability: Durable(持久的),Transiant(短暂的)。
- Auto delete:当有队列或交换机绑定了本交换机,在队列或者交换机都又进行了解绑后,自动删除
- Internal: 是否为内部使用。true 表示为内部交换机,客户端无法直接向该交换机发送消息。
Arguments:
- alternate-exchange: 备份交换机,当消息无法路由到具体队列时,将交给备份交换机处理。
1.3 队列
消息只能存在于队列中,下面看一下队列都有哪些属性。
- Type: Classic,Quorum
- Durability: Durable(持久的),Transiant(短暂的)
- Auto delete: 当有消费者订阅,然后所有的消费者又都断开连接,则自动删除
Arguments:
- x-message-ttl:
Message在Queue中存活时间,超时将被丢弃 - x-expires:
Queue在没有被使用的情况下,过期时间 - x-max-length:
Queue中可以存放的最大消息数,超过将被丢弃 - x-max-length-bytes:
Queue中可以存放最大消息体大小,超过将被丢弃 - x-overflow:
Queue溢出后的行为,drop-head、reject-publish、reject-publish-dlx。 - x-single-active-consumer: 确保只有一个消费者订阅,当出现异常时自动转向另外一个。
- x-max-priority: 队列支持的最大优先级,不设置将不支持。
- x-dead-letter-exchange: 当
Message被rejected或expire时,将会被重新发布到哪个交换机。 - x-dead-letter-routing-key: 当成为死信时,使用的
RoutingKey,未设置时则使用原始Key。 - x-queue-mode: 当设置为
lazy时,会将消息尽可能的放置到磁盘上,以减少内存使用。 - x-queue-master-locator: 将队列设置为主节点定位模式。
- x-message-ttl:
2 使用场景
应用场景一般为三类: 异步、解耦、削峰填谷。
2.1 异步
异步一般是指: 同一个系统内,使用队列将请求和响应异步化,不阻塞主线程,从而获得更高的处理速度,以提升系统性能。
最早在做商城项目时。用户下单付款后先更新本地订单记录,然后再向第三方物流系统推送待发货消息、向用户发放订单相关站内信、并可能触发积分赠送及推荐人的返利计算、以及可能触发相关营销规则发放优惠券等操作。

2.2 解耦
解耦一般指: 不同系统间,通过队列方式进行通信,使系统间不至于过度依赖,减少系统间耦合性。
在最近的项目中,有做的一个事件上报系统,其实就是各个系统都接入。每个系统即可做生产者、也可以做消费者。比如用户在下单后,需要给推荐人赠送积分、向外部CRM同步商机已成单状态等。

2.3 削峰填谷
削峰填谷一般指: 利用队列作为缓冲,将短时大流量缓存起来,由消费者来决定处理速度。使得系统负载趋于平稳,从而提高系统稳定性。
在做用户增长业务相关,用户由落地页提交数据至内部系统,内部系统会将数据简单处理后推送到外部CRM系统,销售在跟客户沟通后,会将线索转换为商机。在这个转换过程中,会由CRM向内部系统推送数据。内部系统会根据传递过来的数据进行各种操作,如创建、更新家长,创建、更新学生,以及各种附加业务信息等。

3 常见问题
3.1 消息重复问题
消息重复的场景很多,比如系统出错、调用超时重试机制、消息消费异常时ReQueue操作等情况。很多时候为了保证消息的可靠传递,会保证消息at-least-once。这种情况下基本无法保证不重复发送,所以消费端要保证幂等性。
既然提到重复性,必然要有重复的依据。比如订单号,同一系统内不允许重复。
- 可借助数据库的
唯一索引,也可借助Redis来保证数据唯一。 - 如果没有重复依据,只能大概根据参数值按一定规则做哈希处理,不过这种可能存在误判和漏判问题。
3.2 消息堆积
消费堆积,无非就是消费速度赶不上生产速度。产生的原因有很多,消费者异常出现消费变慢问题、生产者突发大流量等情况。
解决方案要同时考虑生产者和消费者。发生堆积时,将部分生产者降级,关闭非核心业务,减少消息产生。消费者优化性能,将堆积消息临时转移至新队列,启用新的消费者去消费。
3.3 消息丢失问题
从整个流程考虑,生产者、队列、消费者三方面。
- 生产者: 保证消息成功推送到队列。
- 队列: 保证已推送到队列中的数据不会丢失。
- 消费者: 保证已消费的数据被正确处理。
4 后记
系统设计没有银弹。在引入一个中间件时,要综合考虑、权衡利弊。引入中间件,能解决一些问题,但可能会带来更多的问题。
做好系统监控,像消费堆积有些场景下是可预知的,比如临时做活动或者低价促销之类造成的订单激增。而有些像系统故障类,无法提前预知,则需要监控系统做到及时告警,提前介入处理。
echo '5Y6f5Yib5paH56ugOiDmjpjph5Eo5L2g5oCO5LmI5Zad5aW26Iy25ZWKWzkyMzI0NTQ5NzU1NTA4MF0pL+aAneWQpihscGUyMzQp' | base64 -d


**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。