
推理链(CoR):多范式融合,解锁大语言模型数学推理新高度
📖阅读时长:25分钟
🕙发布时间:2025-02-05
近日热文:全网最全的神经网络数学原理(代码和公式)直观解释
欢迎关注知乎和公众号的专栏内容
LLM架构专栏
知乎LLM专栏
知乎【柏企】
公众号【柏企科技说】【柏企阅文】

大语言模型(LLMs)常常依赖单一范式推理,这在不同任务中限制了它们的发挥。在论文[1]里,作者提出了推理链(Chain-of-Reasoning,简称CoR )这一全新统一框架。它整合了自然语言推理(NLR)、算法推理(AR)和符号推理(SR)等多种推理范式,实现协同合作。CoR运用不同推理范式生成多个可能答案,再综合成一个连贯的最终结果。
如下图(c)所示,CoR能针对给定问题进行多范式推理,运用不同范式得出多个潜在答案,然后总结为最终答案。

实验结果显示,CoR-Math-7B性能远超当前的最优模型(SOTA models)。在定理证明任务上,比GPT-4的绝对准确率提升了41.0%;在算术任务中,相较于基于强化学习(RL)的方法,也有7.9%的提升。
链式推理框架
概述
对于一个数学问题$x$,大语言模型($P$)可以通过多种推理范式来推断结果$y$。每个推理范式$\tau$包含$n$个推理路径$\{rp1, …, rpn\}$ 。
根据该框架,训练流程包含三个关键阶段,如下图所示:

- 收集多范式数学(MPM)数据集:该数据集有着基于多种推理范式的深度推理路径。
- 引入渐进式范式训练(PPT)策略:用于塑造模型的推理行为,让模型逐步掌握更多推理范式。
- 利用训练好的LLM进行零样本推理:支持深度可变的多范式推理,并通过顺序多范式采样(SMPS)探索多样化的解决方案空间。
收集数据集
为实现CoR训练,我们对传统单一范式训练数据集进行扩展,纳入多种推理范式,表示为$<x, NLR, SR, AR, y >$。
第一阶段:重建和扩展
- 引入通用文本模板:专为多范式推理设计(见下图)。该模板规范了不同推理范式的位置,定义了它们之间的关系,能适应各种推理深度,支持不同范式的灵活组合。
- 数据集预处理:对Numina-TIR和Lean-Workbook数据集分两步处理。首先去除无对应答案的样本,然后借助强大的大语言模型(如GPT-4o)进一步重建和扩展数据集。
- 开发定制提示:为每个种子数据集开发特定提示$p_s$(如下图所示)。
- 人工审查:对所有样本进行人工审核。


- 第二阶段:修订
MPM-raw数据集与Lean证明器交互,验证证明步骤,以此指导推理路径的筛选和修改。具体过程是将证明$\tau_{SR}$提交给证明器,如果证明器成功完成证明且无错误返回,整个多范式推理路径就会被收集到MPM数据集中;否则,证明器返回的错误信息$\varepsilon$会输入到修订模型$P_R$中。该模型基于提示$p_{\varepsilon}$生成修订后的证明$\widetilde{\tau}_{SR}$ ,关系如下:

修订后的证明$\widetilde{\tau}_{SR}$会重新提交给Lean证明器验证。这个迭代过程最多进行64次,直到证明器验证$\widetilde{\tau}_{SR}$正确为止。我们使用DeepSeek-Prover-V1.5作为修订模型。最终,MPM数据集包含82,770个问题和167,412个多范式推理解决方案。
训练
我们引入渐进式范式训练(PPT)策略,帮助大语言模型逐步掌握更多推理范式。该训练框架通过分阶段引入不同类型的推理数据,逐步拓展模型的推理能力,每个训练阶段采用不同的推理范式组合。
- 阶段➀:由于自然语言(NL)在语言模型预训练数据中占主导,我们修改原始的Numina-CoT数据集,创建Numina-CoT∗作为初始化教学阶段。基于问题$x$,模型执行推理$\tau_{NLR}$并生成答案$y$,生成的序列为$z = [x]\tau_{NLR}y$,其中$[x]$代表输入的标记。简单起见,单个样本的损失函数如下:

其中$\theta$代表模型参数,$z_t$是生成序列中的第$t$个标记,$z_{<t}$表示生成序列中第$t$个标记之前的所有标记。
- 阶段➁:考虑到预训练数据中有一定比例的代码语料库,我们将训练数据集扩展为包含NLR和AR两种范式。类似Numina-CoT∗ ,我们修改原始的Numina-TIR创建Numina-TIR∗ 。使用这个修改后的数据集,生成的序列为$z = [x]\tau_{NLR}\tau_{AR}y$。
- 阶段➂:利用MPM数据集,我们将训练数据进一步扩展为包含三种推理范式,此时$z$为$[x]\tau_{NLR}\tau_{AR}\tau_{SR}y$ 。经过完整的PPT阶段训练,CoR-Math-7B模型不仅掌握了NLR和AR,还能进行严格的逻辑SR推理。
推理
我们提出一种结合可变推理深度和顺序多范式采样的推理方法,用于解决综合数学任务,使模型能根据任务需求调整推理过程。
- 具有可变推理深度的提示:一开始,提示模型进行NLR,激活预训练语料库中与自然语言相关的广泛知识模式。随后,根据具体问题类型调整推理方法。例如在定理证明场景中,模型切换到更适合形式推导的SR。由于SR阶段模型输出基于Lean 4构建,相关证明片段可提取作为最终答案。这种灵活的范式转换有效捕捉了不同范式的独特推理模式,在各种场景下都展现出良好的适应性。
- 顺序多范式采样(SMPS):该方法让模型通过跨不同范式顺序采样生成输出。例如在双范式推理场景中,模型首先为初始推理范式$\tau_1$实例化$J$个不同路径;然后对于每个$\tau_1$路径,再为次要推理范式$\tau_2$实例化$K$个可能路径。这样的分层采样过程总共会产生$J×K$个潜在响应,记为$y$。总之,SMPS方法利用推理路径的组合扩展,全面探索基于范式的多样化解决方案空间。
实验
指标
准确性是评估所有数据集性能的主要指标。
实施细节
我们使用PPT方法,在MPM数据集上对广泛应用的DeepSeek-Math-Base 7B和Llama-3.1 8B模型进行微调。除非特别说明,CoR-Math-7B模型基于DeepSeek-Math-Base 7B。在PPT方法的各个阶段,学习率设为$2e^{-5}$,热身率为1%。为提升计算效率,训练过程采用DeepSpeed ZeRO Stage 3分布式优化,并结合Flash-Attention技术。
基线
- 通用数学模型:包含当前最优的通用数学模型,如Mustard、DeepSeek-Math、InternLM-Math、Llama-3.1、Mistral和Llemma。
- 特定任务数学模型:针对数学优化的特定任务,考虑了多个专家模型。在算术计算方面,包含多个经过专门强化的模型,如Qwen2.5-Math、WizardMath、MetaMath等;在定理证明方面,考虑了LLM-Step、GPT-f、Lean-STaR等多个改进显著的最优模型。
- 基础模型和专有模型:涵盖当前先进的开源基础模型,像Llama-3.1、Mistral、Mixtral,以及GPT-4、GPT-4o和o1-mini等专有模型 。
结果
与通用数学模型的比较:下表展示了CoR-Math-7B与三类通用数学推理器(专有模型、基础模型和通用数学模型(GMM))在三个数学基准测试中的总体对比。结果显示,CoR-Math-7B在零样本设置下,在三个具有挑战性的基准测试中均表现最佳,充分体现了其强大的综合数学推理能力。主要发现如下:
- 算术计算任务:CoR-Math-7B在所有算术计算基准测试中成绩最优。例如在MATH数据集上,比InterLM2-Math-Plus-7B的绝对准确率提高了13.7%。
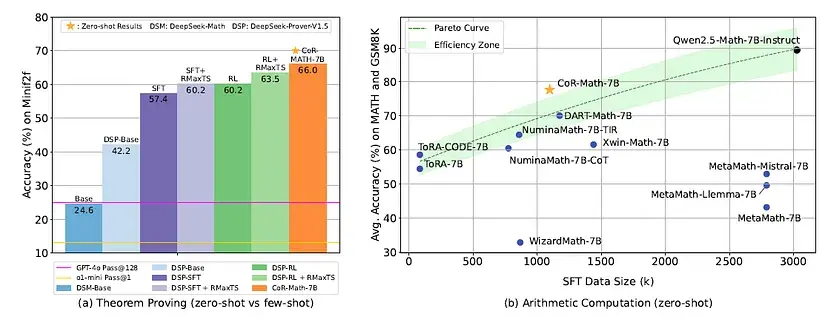
- 定理证明任务:CoR-Math-7B在MiniF2F测试中取得了最佳零样本结果,在少样本设置下,绝对准确率比专有的GPT-4o模型还高出41%。
- 零样本与少样本对比:CoR-Math-7B的零样本结果优于其他模型的所有少样本结果。
- 与定理证明专家模型的比较:下表呈现了CoR-Math-7B的零样本性能,以及MiniF2F基准测试中优化模型的少样本性能。结果表明,CoR-Math-7B在MiniF2F上的零样本性能十分出色,无需示例即可达到66.0%的准确率,而其他竞争方法则需要少量示例。


- 与算术计算专家模型的比较:下表展示了算术任务在MATH和GSM8K基准测试中的零样本性能,以及监督微调(SFT)阶段的数据规模。结果显示,CoR-Math-7B在算术计算方面与专家模型相比极具竞争力。与ToRA和NuminaMath等仅将代码作为工具、缺乏完整推理的方法相比,具有多范式推理能力的CoR-Math-7B在所有基准测试中都更胜一筹。

关于推理层次结构的讨论:范式、路径和步骤
如下图所示,本文认为大语言模型生成的推理文本具有推理层次结构,包含推理范式、推理路径和推理步骤三个层级:

- 推理步骤:是基本单元,由一个或多个标记组成,代表求解过程的一个不完整阶段。
- 推理路径:由多个推理步骤构成,形成一条完整的推理链,通常包含最终答案和求解过程。
- 推理范式:包含一个或多个推理路径,往往有多个潜在最终答案,需要通过摘要模块等方法提取最终答案。此外,推理范式使用单一知识媒介,如自然语言。
下图对比了前沿研究中的几种推理范式:

- 深度推理:特点是推理路径依次串联。
- 交错推理:在主导范式中融入辅助指导方法。
- 多范式推理(即本文提出的CoR):旨在利用不同推理范式间的协同效应。
结论
本文提出推理链(CoR)这一创新统一推理框架,它将自然语言推理、算法推理和符号推理有机结合,用于解决数学问题。该方法展现了在推理过程中整合多种推理范式的潜力,让语言模型能够高效应对复杂数学挑战。CoR在具有挑战性的数学推理任务中性能卓越,在MATH和MiniF2F等基准测试中,大幅超越了现有的单一范式方法。
论文链接:https://arxiv.org/abs/2501.11110
引用:Chain-of-Reasoning: Towards Unified Mathematical Reasoning in Large Language Models via a Multi-Paradigm Perspective by Yu et al. arXiv:2501.11551
本文由mdnice多平台发布







**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。