SF
deephub
deephub
注册登录
关注博客
注册登录
主页
关于
RSS
Numpy中数组和矩阵操作的数学函数
deephub
2023-02-08
阅读 3 分钟
1k
Numpy 是一个强大的 Python 计算库。它提供了广泛的数学函数,可以对数组和矩阵执行各种操作。本文中将整理一些基本和常用的数学操作。
3个用于时间序列数据整理的Pandas函数
deephub
2023-02-07
阅读 3 分钟
823
本文将演示 3 个处理时间序列数据最常用的 pandas 操作首先我们要导入需要的库: {代码...} 本文使用的数据集非常简单。它只有 1 列,名为 VPact (mbar),表示气候中的气压。该数据集的索引是日期时间类型:我们也可以应用 pd.to_datetime(df.index) 来制作日期时间类型的索引。本地化时区✏️本地化是什么意思?本地化意...
使用JAX实现完整的Vision Transformer
deephub
2023-02-06
阅读 9 分钟
1.4k
本文将展示如何使用JAX/Flax实现Vision Transformer (ViT),以及如何使用JAX/Flax训练ViT。Vision Transformer在实现Vision Transformer时,首先要记住这张图。以下是论文描述的ViT执行过程。从输入图像中提取补丁图像,并将其转换为平面向量。投影到 Transformer Encoder 来处理的维度预先添加一个可学习的嵌入([class]...
论文推荐:ACMix整合self-Attention和Convolution (ACMix)的优点的混合模型
deephub
2023-02-05
阅读 4 分钟
1.2k
混合模型ACmix将自注意与卷积的整合,同时具有自注意和卷积的优点。这是清华大学、华为和北京人工智能研究院共同发布在2022年CVPR中的论文
使用谱聚类(spectral clustering)进行特征选择
deephub
2023-02-04
阅读 4 分钟
1.4k
谱聚类是一种基于图论的聚类方法,通过对样本数据的拉普拉斯矩阵的特征向量进行聚类,从而达到对样本数据聚类的目的。谱聚类可以理解为将高维空间的数据映射到低维,然后在低维空间用其它聚类算法(如KMeans)进行聚类
Pandas的apply, map, transform介绍和性能测试
deephub
2023-02-03
阅读 8 分钟
1.4k
apply函数是我们经常用到的一个Pandas操作。虽然这在较小的数据集上不是问题,但在处理大量数据时,由此引起的性能问题会变得更加明显。虽然apply的灵活性使其成为一个简单的选择,但本文介绍了其他Pandas函数作为潜在的替代方案。
2023 年 1 月的5篇深度学习论文推荐
deephub
2023-02-02
阅读 2 分钟
1.1k
伯克利分校的研究人员开发了一种使用人工指令编辑图像的新方法。通过结合两个预训练模型(一个语言模型和一个文本到图像模型)的知识,他们能够生成一个大型图像编辑数据集。使用这些数据来训练他们的模型,称为 InstructPix2Pix。该模型能够快速执行编辑,这种新方法允许按照人工指令(GitHub 链接)进行更高效和准确的...
在 PyTorch 中使用梯度检查点在GPU 上训练更大的模型
deephub
2023-02-01
阅读 9 分钟
950
作为机器学习从业者,我们经常会遇到这样的情况,想要训练一个比较大的模型,而 GPU 却因为内存不足而无法训练它。当我们在出于安全原因不允许在云计算的环境中工作时,这个问题经常会出现。在这样的环境中,我们无法足够快地扩展或切换到功能强大的硬件并训练模型。并且由于梯度下降算法的性质,通常较大的批次在大多数...
CRPS:贝叶斯机器学习模型的评分函数
deephub
2023-01-31
阅读 4 分钟
2.7k
连续分级概率评分(Continuous Ranked Probability Score, CRPS)或“连续概率排位分数”是一个函数或统计量,可以将分布预测与真实值进行比较。
DeepTime:时间序列预测中的元学习模型
deephub
2023-01-29
阅读 7 分钟
1.6k
DeepTime,是一个结合使用元学习的深度时间指数模型。通过使用元学习公式来预测未来,以应对时间序列中的常见问题(协变量偏移和条件分布偏移——非平稳)。该模型是时间序列预测的元学习公式协同作用的一个很好的例子。
使用OpenAI的Whisper 模型进行语音识别
deephub
2023-01-28
阅读 4 分钟
4.8k
语音识别是人工智能中的一个领域,它允许计算机理解人类语音并将其转换为文本。该技术用于 Alexa 和各种聊天机器人应用程序等设备。而我们最常见的就是语音转录,语音转录可以语音转换为文字记录或字幕。
监控Python 内存使用情况和代码执行时间
deephub
2023-01-27
阅读 4 分钟
2.4k
在开发过程中,我很确定我们大多数人都会想知道这一点,而且通常情况下存在开发空间。在本文中总结了一些方法来监控 Python 代码的时间和内存使用情况。
使用CNN进行2D路径规划
deephub
2023-01-26
阅读 4 分钟
2.8k
卷积神经网络(CNN)是解决图像分类、分割、目标检测等任务的流行模型。本文将CNN应用于解决简单的二维路径规划问题。主要使用Python, PyTorch, NumPy和OpenCV。
这20个Pandas函数可以完成80%的数据科学工作
deephub
2023-01-25
阅读 10 分钟
1.2k
Pandas 是数据科学社区中使用最广泛的库之一,它是一个强大的工具,可以进行数据操作、清理和分析。本文将提供最常用的 Pandas 函数以及如何实际使用它们的样例。我们将涵盖从基本数据操作到高级数据分析技术的所有内容,到本文结束时,你会深入了解如何使用 Pandas 并使数据科学工作流程更高效。
使用Stable-Diffusion生成视频的完整教程
deephub
2023-01-24
阅读 9 分钟
2.1k
本文是关于如何使用cuda和Stable-Diffusion生成视频的完整指南,将使用cuda来加速视频生成,并且可以使用Kaggle的TESLA GPU来免费执行我们的模型。
7个流行的强化学习算法及代码实现
deephub
2023-01-23
阅读 12 分钟
2.6k
目前流行的强化学习算法包括 Q-learning、SARSA、DDPG、A2C、PPO、DQN 和 TRPO。 这些算法已被用于在游戏、机器人和决策制定等各种应用中,并且这些流行的算法还在不断发展和改进,本文我们将对其做一个简单的介绍。
2023 年8个ChatGPT 的替代品
deephub
2023-01-22
阅读 4 分钟
3k
OpenAI 于 2022 年 11 月下旬推出的 ChatGPT 在网络世界引起了不小的轰动。它不仅引起了社交媒体用户的关注,也引起了各大媒体的关注。
8种时间序列分类方法总结
deephub
2023-01-21
阅读 8 分钟
3.4k
对时间序列进行分类是应用机器和深度学习模型的常见任务之一。本篇文章将涵盖 8 种类型的时间序列分类方法。这包括从简单的基于距离或间隔的方法到使用深度神经网络的方法。这篇文章旨在作为所有时间序列分类算法的参考文章。
深度学习中高斯噪声:为什么以及如何使用
deephub
2023-01-20
阅读 9 分钟
2.8k
在数学上,高斯噪声是一种通过向输入数据添加均值为零和标准差(σ)的正态分布随机值而产生的噪声。 正态分布,也称为高斯分布,是一种连续概率分布,由其概率密度函数 (PDF) 定义:
可视化VIT中的注意力
deephub
2023-01-19
阅读 14 分钟
2k
2022年, Vision Transformer (ViT)成为卷积神经网络(cnn)的有力竞争对手,卷积神经网络目前是计算机视觉领域的最先进技术,广泛应用于许多图像识别应用。在计算效率和精度方面,ViT模型超过了目前最先进的(CNN)几乎四倍。
CycleMLP:一种用于密集预测的mlp架构
deephub
2023-01-18
阅读 4 分钟
1.1k
MLP-Mixer, ResMLP和gMLP,其架构与图像大小相关,因此在目标检测和分割中是无法使用的。而CycleMLP有两个优点。(1)可以处理各种大小的图像。(2)利用局部窗口实现了计算复杂度与图像大小的线性关系。
Jupyter Lab 的 10 个有用技巧
deephub
2023-01-17
阅读 3 分钟
1.1k
JupyterLab是 Jupyter Notebook「新」界面。它包含了jupyter notebook的所有功能,并升级增加了很多功能。它最大的更新是模块化的界面,可以在同一个窗口以标签的形式同时打开好几个文档,同时插件管理非常强大,使用起来要比jupyter notebook高大尚许多。
YOLO家族系列模型的演变:从v1到v8(下)
deephub
2023-01-16
阅读 6 分钟
2.9k
“You Only Learn One Representation: Unified Network for Multiple Tasks”2021/05, [链接]
YOLO家族系列模型的演变:从v1到v8(上)
deephub
2023-01-15
阅读 11 分钟
2.4k
YOLO V8已经在本月发布了,我们这篇文章的目的是对整个YOLO家族进行比较分析。了解架构的演变可以更好地知道哪些改进提高了性能,并且明确哪些版本是基于那些版本的改进,因为YOLO的版本和变体的命名是目前来说最乱的,希望看完这篇文章之后你能对整个家族有所了解。
使用Stable Diffusion和Pokedex的描述生成神奇宝贝图片
deephub
2023-01-14
阅读 7 分钟
1.4k
在本文中,我将展示如何从神奇宝贝系列不同游戏中的Pokedex条目中获取神奇宝贝描述,并使用Stable Diffusion根据这些藐视生成图片,这样可以看看AI如何解释这些描述的。这篇文章中,我只生成了最初的150个神奇宝贝,如果需要其他的可以自行尝试。
论文推荐:谷歌Masked Generative Transformers 以更高的效率实现文本到图像的 SOTA
deephub
2023-01-13
阅读 2 分钟
1k
基于文本提示的生成图像模型近年来取得了惊人的进展,这得益于新型的深度学习架构、先进的训练范式(如掩码建模)、大量图像-文本配对训练数据的日益可用,以及新的扩散和基于掩码的模型的发展。
2022年深度学习在时间序列预测和分类中的研究进展综述
deephub
2023-01-12
阅读 7 分钟
1.9k
2022年整个领域在几个不同的方面取得了进展,本文将尝试介绍一些在过去一年左右的时间里出现的更有前景和关键的论文,以及Flow Forecast [FF]预测框架。
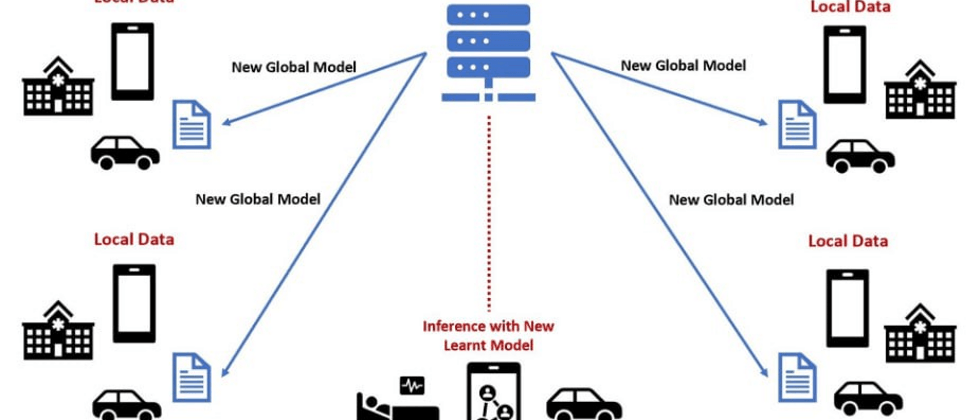
联邦学习 (FL) 中常见的3种模型聚合方法的 Tensorflow 示例
deephub
2023-01-11
阅读 3 分钟
1.5k
联合学习 (FL) 是一种出色的 ML 方法,它使多个设备(例如物联网 (IoT) 设备)或计算机能够在模型训练完成时进行协作,而无需共享它们的数据。
Diffusion 和Stable Diffusion的数学和工作原理详细解释
deephub
2023-01-10
阅读 6 分钟
2.6k
扩散模型的兴起可以被视为人工智能生成艺术领域最近取得突破的主要因素。而稳定扩散模型的发展使得我们可以通过一个文本提示轻松地创建美妙的艺术插图。所以在本文中,我将解释它们是如何工作的。
TensorFlow和PyTorch的实际应用比较
deephub
2023-01-09
阅读 8 分钟
1.5k
TensorFlow和PyTorch是两个最受欢迎的开源深度学习框架,这两个框架都为构建和训练深度学习模型提供了广泛的功能,并已被研发社区广泛采用。但是作为用户,我们一直想知道哪种框架最适合我们自己特定项目,所以在本文与其他文章的特性的对比不同,我们将以实际应用出发,从性能、可伸缩性和其他高级特性方面比较TensorFl...
上一页
1
…
More
23
24
25
(current)
26
27
…
More
下一页
上一页
25
(current)
下一页