SF
监控系统和运维开发
监控系统和运维开发
注册登录
关注博客
注册登录
主页
关于
RSS
不对全文内容进行索引的Loki到底优秀在哪里,可以占据一部分日志监控领域
ning1875
2021-05-11
阅读 9 分钟
11.8k
k8s零基础入门运维课程k8s零基础入门运维课程,计算存储网络和常见的集群相关操作k8s纯源码解读教程(3个课程内容合成一个大课程)k8s底层原理和源码讲解之精华篇k8s底层原理和源码讲解之进阶篇k8s纯源码解读课程,助力你变成k8s专家k8s运维进阶调优课程k8s运维大师课程k8s管理运维平台实战k8s管理运维平台实战前端vue后端...
prometheus range_query源码解读和高基数判定依据query_log各阶段统计耗时原理
ning1875
2021-05-06
阅读 9 分钟
7.3k
在时序数据库中的高基数问题可以看我之前写的文章高基数和prometheus中判定高基数的三种方法今天我们讲解下其中第二种判定方法的range_query 原理并且讲解下query_log统计的原理总结range_query查询过程解析参数设置超时并设置opentracing根据queryEngine初始化query并解析promqlexec函数先设置 ExecTotalTimeexec函数进...
别再乱用prometheus联邦了,分享一个multi_remote_read的方案来实现prometheus高可用
ning1875
2021-04-29
阅读 4 分钟
6.2k
视频教程教程地址前言我看到很多人会这样使用联邦:联邦prometheus 收集多个采集器的数据实在看不下下去了,很多小白还在乱用prometheus的联邦其实很多人是想实现prometheus数据的可用性,数据分片保存,有个统一的查询地方(小白中的联邦prometheus)而且引入m3db等支持集群的tsdb可能比较重具体问题可以看我之前写的文章...
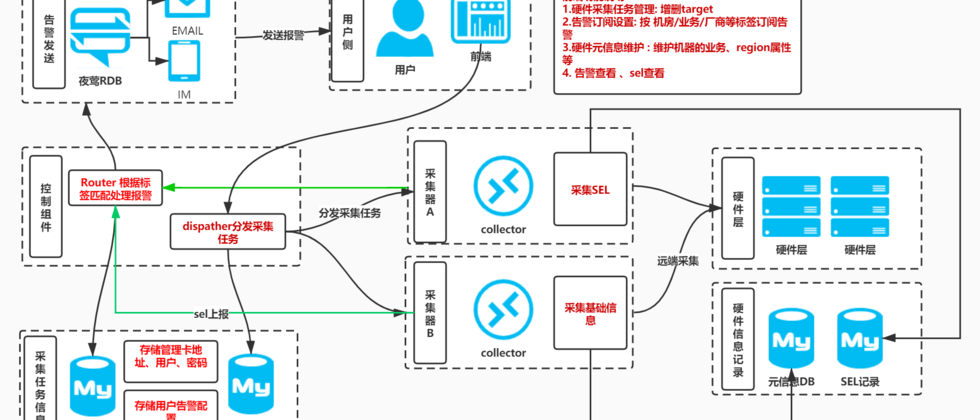
硬件监控原理ipmi、redfish、sel
ning1875
2021-04-08
阅读 4 分钟
6.2k
都要采集什么采集内容举例用途时序数据 metrics如传感器温度度数、风扇转速可以根据所有机器电流得出机房电流等事件日志 sel如内存可纠正错误Mem ECC Warning告警触发换配件工单等硬件资产信息 info如获取机器上有多少块硬盘,插槽信息等可以做资产盘点硬件信息info意义说明能采集到多细的粒度 {代码...} 利用详细的信息...
k8s环境中监控不通问题排查思路
ning1875
2021-04-02
阅读 7 分钟
3.1k
k8s中的监控原理、prometheus采集原理 可以看这个文章k8s监控指标汇总,prometheus采集k8s原理解析k8s-mon项目介绍项目地址[链接]视频介绍[链接]kube-stats-metrics 没数据排查思路 dns问题首先观察k8s-mon-deployment的日志 {代码...} 排查dns,在node上请求coredns 服务 {代码...} 在node上请求 coredns 解析 kube-sta...
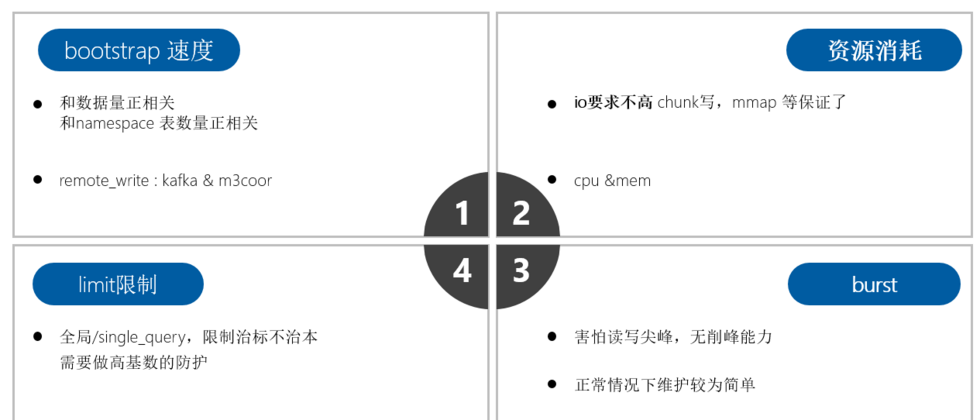
m3db资源开销,聚合降采样,查询限制等注意事项
ning1875
2021-03-24
阅读 5 分钟
4.2k
视频教程教程地址m3db资源开销问题:无需用ssd,也没必要做raid正常情况下m3db 对io要求不高因为和prometheus一样设计时采用了mmap等技术,所以没必要采用ssd和open-falcon/夜莺等采用rrd不同,rrd 单指标单文件,很耗iocpu和内存开销写峰很危险,原因很简单一条新的数据写入的时候,需要申请block,索引等一系列内存,...
自研代理实现夜莺分机房数据全局查询
ning1875
2021-03-12
阅读 3 分钟
1.8k
项目地址n9e-transfer-proxy架构说明分析前端请求发现在使用m3db作为后端时需要下面4个接口 {代码...} 所以proxy只需要实现上述4个接口的代理即可将原始请求并发打向后端所有transfer接口将数据merge后在返回前端在使用m3db作为存储时,有布隆过滤器顶在最前端,所以查询不存在该机房的数据所引发的资源开销不大优化点可...
prometheus 两种分位值histogram和summary对比,histogram线性插值法原理说明
ning1875
2021-02-02
阅读 4 分钟
8.7k
前言prometheus官方文档中对于两种类型的对比说明下面我总结一些对比点对比点histogramsummary查询表达式对比histogram_quantile(0.95, sum(rate(http_request_duration_seconds_bucket[5m])) by (le))http_request_duration_seconds_summary{quantile="0.95"}所需配置选择合适的buckets选择所需的φ分位数和滑动窗口。其...
prometheus promql 实用举例
ning1875
2021-01-21
阅读 2 分钟
5.3k
举例:pod状态 kube_pod_status_phase{pod!~"filebeat.*",job="kube-state-metrics", namespace !~"druid",phase=~"Pending|Unknown"}
k8s监控指标汇总,prometheus采集k8s原理解析
ning1875
2021-01-08
阅读 17 分钟
27.8k
apiserver可以采用tls双向认证,所以需要提供证书 {代码...} prometheus通过 sa,clusterrolebinding来解决token、证书挂载问题sa等配置: prometheus yaml中需要配置对应的saserviceAccountName {代码...}
开源项目 : prome-route: 使用反向代理实现prometheus分片
ning1875
2020-09-10
阅读 2 分钟
2.2k
开源项目地址:项目地址: [链接]PS: 这是一个仅用时半天就写完的项目架构图prometheus HAprometheus本地tsdb性能出色,但是碍于其没有集群版本导致HA较差实现手段注意这些手段都是要数据的统一存储可以通过remote_write 到一个提供HA的tsdb存储中通过联邦收集到一个prometheus里问题来了,搞不定集中式的tsdb集群,或者集...
开源项目: pre_query: 给prometheus 重(heavy_query)查询提速
ning1875
2020-09-09
阅读 7 分钟
4k
顾名思义 就是查询表现出来返回时间较长,对应调用服务端资源较多的查询一般我们定义在1小时内的range_query 响应时间超过3秒则认为较重了
开源项目: self_upgrade: C/S架构中 agent如何自升级(以falcon-agent为例)
ning1875
2020-07-27
阅读 9 分钟
4.7k
项目地址代码地址 [链接]前言在我们日常运维/运维开发工作中各种系统主要分为两大流派本文主要讨论下有agent侧一些注意事项客户端服务端的C/S架构优点c/s架构相比于基于ssh的并发和吞吐量要高的多利用agent可做的事情很多以及更精准的控制缺点功能更新需要升级agentagent如果保活是个头疼的问题机器上agent过多如何管理...
prometheus 本地存储解析及其使用的那些"黑科技"
ning1875
2020-07-15
阅读 13 分钟
5.1k
本文代码基于prometheus 2.19.2分析 基本概念 什么是tsdb {代码...} prometheus 基本概念 sample 数据点 {代码...} sample代表一个数据点 size:16byte: 包含 1个8byte int64时间戳和1个8byte float64 value Label 标签 {代码...} 一对label 比如 job="ec2" Labels 标签组 {代码...} 就是metric 一个指标的所有tag values...
open-falcon-alarm 代码分析
ning1875
2020-07-07
阅读 7 分钟
2.9k
高优先级报警比如p0: judge产生报警事件-->写入redis event:p0队列 -->alarm消费-->获取发送对象并处理调用回调函数(如果有)-->根据策略不同生成不同通道的报警(im,sms,mail,phone)等-->写入redis各个通道的发送队列 /im /sms /mail /phone -->发送报警的worker取出报警发送
promethues系列之:追踪k8s容器指标的打tag的流程
ning1875
2020-07-06
阅读 4 分钟
4k
k8s中容器资源的监控 在promethues中如何配置采集容器指标 采用promethues的kubernetes_sd_configs中 node级别的role {代码...} cadvisor架构图 cadvisor中 POD 在查看cadvisor代码时发现有一种container_name=="POD"的容器,查了下是 k8s中的pause pod 下面追踪下打tag的过程:以pod cpu使用率为例 kubelet最终tag 对应c...
开源项目:polymetric:监控聚合器系列之: open-falcon新聚合器polymetric
ning1875
2020-07-04
阅读 7 分钟
3.4k
简单来说:需要将分散的大量监控数据按照一定的维度(idc/service)及一定的算法(avg/sum/max/min/quantile分位)得到一个结果值
open-falcon 聚合器aggregator代码解析
ning1875
2020-07-04
阅读 6 分钟
2.7k
总结:aggregator聚合器就是从falcon_portal.cluster表中取出用户在页面上配置的表达式,然后解析后,通过api拿到对应机器组的所有机器,通过api查询graph数据算出一个值重新打回transfer作为一个新的点。
解读两个一致性哈希算法
ning1875
2020-06-11
阅读 9 分钟
2.8k
最重要的一点忘了写了:一致性哈希算法为啥能在节点变更的时候只有少量key迁移是因为sortkeys列表其实就是一个哈希环,客户端的哈希值和存量的节点哈希值在有序的sortkeys列表中的相对位置没有变,变的是下线节点前面的哈希到再前面一个之间的值所以变更率为:1-n/m
我对开源版本openfalcon的变更
ning1875
2020-06-11
阅读 5 分钟
3.3k
ps 基于open-falcon做监控现在有点落伍了,目前我这里有更好的方案,感兴趣的github issue留言 地址 [链接] 我重写了聚合器,重写聚合器目的 poly_metric VS aggregator 解决endpoint多的聚合断点问题 解决聚合器单点问题,使得横向扩展得以实现 解耦聚合器各个单元,可以方便的增加新的聚合入口和聚合策略 .falcon agent...
开源项目 : dynamic-sharding: 解决pushgateway 高可用HA问题
ning1875
2020-06-10
阅读 4 分钟
8.1k
k8s教程说明k8s底层原理和源码讲解之精华篇k8s底层原理和源码讲解之进阶篇k8s纯源码解读课程,助力你变成k8s专家k8s-operator和crd实战开发 助你成为k8s专家tekton全流水线实战和pipeline运行原理源码解读prometheus全组件的教程01_prometheus全组件配置使用、底层原理解析、高可用实战02_prometheus-thanos使用和源码解...