- 昨天玩了一些小模型后,开始用几个提示尝试绘制确定模型血统的流程图,比如询问关于国家审查话题和其发展的内容,以确定其训练模型。但幸运的是放弃了该努力,因为Sam Paech维护了EQ-Bench,并构建了整个“slop forensics”管道。
- 据 Sam 称,他的工具“为每个模型生成‘slop 轮廓’……然后使用生物信息学工具根据 slop 轮廓的相似性推断谱系树”。简而言之,通过生成和分析每个模型的创造性写作输出,可以构建基于常用和/或独特短语的指纹并进行比较。
- 可以通过访问EQ-Bench并点击“slop”分数旁边的“i”来查看这些轮廓,新的 DeekSeek R1 的轮廓如下:
 。
。 - 有趣的是,Sam 的 slop forensics 显示 DeepSeek 可能已从 OpenAI 的模型切换到 Google 的 Gemini 模型来生成其合成数据,结果 DeekSeek 现在听起来更像 Google 的 LLM 家族,其工具生成的可视化显示了这种戏剧性的切换:
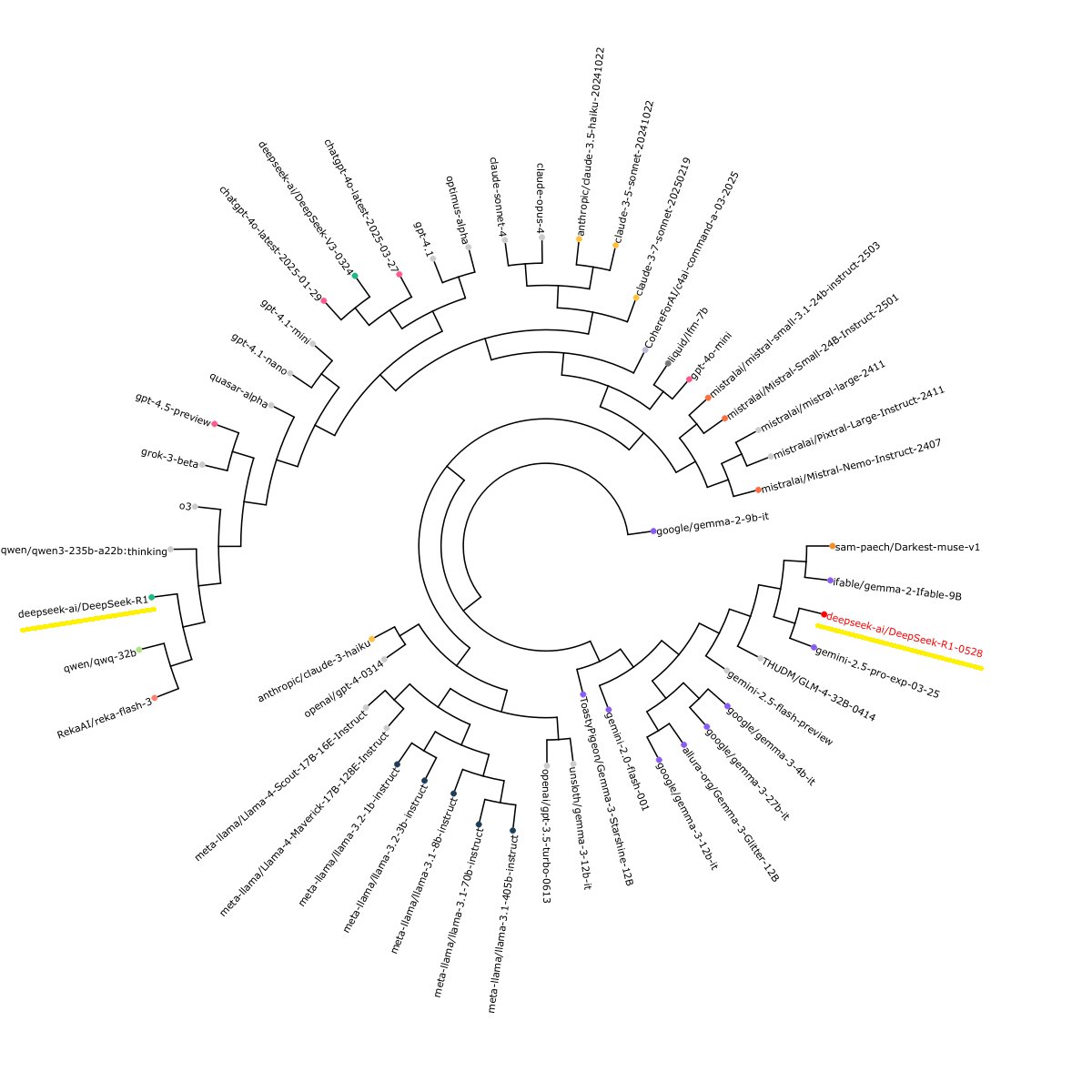 。
。 - 该工具还强调了这些模型是如何趋同的,每个模型在写幻想小说时都使用(以前)独特的名字,如“Elara”,这是我们当前对合成数据依赖的一个潜在影响,尤其是在像创造性写作这样不可验证的领域。
- 如果我们在共享数据集或使用相同模型生成新数据集,转换很可能会发生,这如果我们希望在我们的 LLM 中具有创造力和多样性就不理想。
使用“斜率法医学”来确定模型谱系
阅读 109
**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。