

论文对CornerNet进行了性能优化,提出了CornerNet-Saccade和CornerNet-Squeeze两个优化的CornerNet变种,优化的手段具有很高的针对性和局限性,不过依然有很多可以学习的地方
来源:晓飞的算法工程笔记 公众号
论文: CornerNet-Lite: Efficient Keypoint-BasedObject Detection

Introduction

CornerNet作为Keypoint-based目标检测算法中的经典方法,虽然有着不错的准确率,但其推理很慢,大约需要1.1s/张。虽然可以简单地缩小输入图片的尺寸来加速推理,但这会极大地降低其准确率,性能比YOLOv3要差很多。为此,论文提出了两种轻量级的CornerNet变种:
- CornerNet-Saccade:该变种主要通过降低需要处理的像素数量来达到加速的目的,首先通过缩小的图片来获取初步的目标位置,然后根据目标位置截取附近小范围的图片区域来进行目标的检测,准确率和速度分别可达到43.2%AP以及190ms/张。
- CornerNet-Squeeze:该变种主要通过降低每个像素的处理次数来达到加速的目的,将SqueezeNet和MobileNets的思想融入hourglass提出新的主干网络,准确率和速度分别可达到34.4%AP以及30ms/张。
论文也尝试了将两种变种进行结合,但发现性能反而更差了,主要由于CornerNet-Saccade需要强大的主干网络来生成足够准确的特征图,而CornerNet-Squeeze则是减弱了主干网络的表达能力进行加速,所以两者的结合没有达到更好的效果。
CornerNet-Saccade
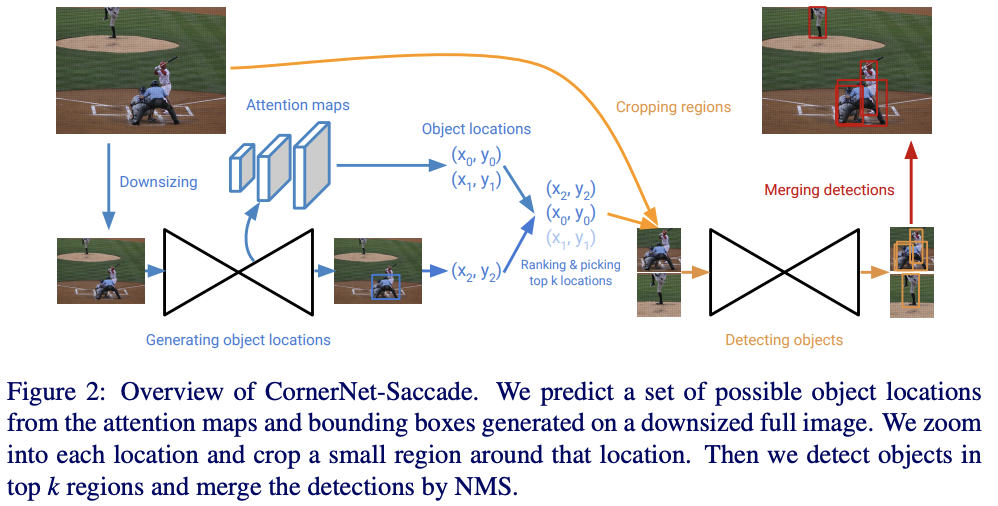
CornerNet-Saccade在可能出现目标的位置的小区域内进行目标检测,首先通过缩小的完整图片预测attention特征图,获得初步的预测框位置以及尺寸,然后在高分辨率图片上截取以该位置为中心的图片区域进行目标检测。
Estimating Object Locations
CornerNet-Saccade首先获取可能出现目标的初步位置及其尺寸:
- 将输入的图片缩小至长边为255像素和192像素两种尺寸,小图进行零填充,使其能同时输入到网络中进行计算。
- 对于缩小的图片,预测3个attention特征图,分别用于小目标(长边<32像素)、中目标(32像素<=长边<=96像素)和大目标(长边>96像素)的位置预测,这样的区分能够帮助判断是否需要对其位置区域进行放大,对于小目标需要放大更大,下一部分会提到。
- Attention特征图来源于hourglass上采样部分的不同模块,尺寸较大的模块特征图输出用于更小的目标检测(主干网络结构后面会介绍),对每个模块输出的特征图使用$3\times 3$Conv-ReLU模块接$1\times 1$Conv-Sigmoid模块生成Attention特征图。
在测试阶段,我们仅处理置信度大于阈值$t=0.3$预测位置,而在训练阶段,将GT的中心在对应特征图上的位置设为正样本,其它设为负样本,使用$\alpha=2$的focal loss进行训练。
Detecting Objects
基于初步的预测框位置和尺寸,CornerNet-Saccade对缩小的原图进行放大后截取以该位置为中心的$255\times 255$的区域进行目标检测。放大主要是为了保证目标足够清晰,根据预测框的初步尺寸对缩小的原图先进行放大,放大比例为$s_s=4>s_m=2>s_l=1$。后续对截取区域的检测使用同样的hourglass网络,最后合并所有的检测结果进行Soft-NMS过滤。检测网络的训练和预测方法跟原版CornerNet一样,结合角点热图、embeddings向量以及偏移值。

这里有一些如图3所示的特殊情况需要特别处理:
- 如果检测结果出现在截取区域的边缘,需要将其去掉,因为该截图区域很可能至包含了目标的一部分。
- 如果目标挨得很近,两者的截取区域会高度重叠,网络很可能产生高度重叠的重复结果。为此,采用类似NMS方法来处理各尺寸预测结果中过近的预测位置,从而提高效率。
另外,为了让检测过程更加高效,论文也进行了以下细节的实现:
- 批量进行截取区域的获取
- 将原图保存在GPU内存中,并且直接在GPU进行原图的放大以及截取
- 批量进行截取区域的检测
Backbone Network
论文设计新的主干网络Hourglass-54,比原CornerNet使用的Hourglass-104包含更少参数且层数更少。Hourglass-54总层数为54层,包含3个hourglass模块,在第一个模块前先下采样两次。每个模块下采样三次并逐步增加维度(384, 384, 512),每个模块中间包含一个512维的残差模块,每个上采样层后面接一个残差模块。
CornerNet-Squeeze
在CornerNet中,大多数的计算时间花在主干网络Hourglass-104的推理。为此,CornerNet-Squeeze结合SqueezeNet和MobileNet来减少Hourglass-104的复杂度,设计了一个新的轻量级hourglass网络。
SqueezeNet的核心在于fire模块,首先通过包含$1\times 1$卷积的squeeze层降低输入特征的维度,然后通过包含$1\times 1$卷积和$3\times 3$卷积的expand层提取特征。MobileNet则采用$3\times 3$深度分离卷积替换标准的$3\times 3$卷积,能够有效地减少网络的参数。

新的模块如表1所示,除了替换残差模块,新主干网络还做了以下的修改:
- 为了降低hourglass模块的最大特征图,在第一个hourglass模块前增加一个下采样模层。对应地,去除每个hourglass模块的一个下采样层。
- 将预测模块的$3\times 3$卷积替换为$1\times 1$卷积。
- 将最近的相邻上采样层替换为$4\times 4$的反卷积。
Experiments
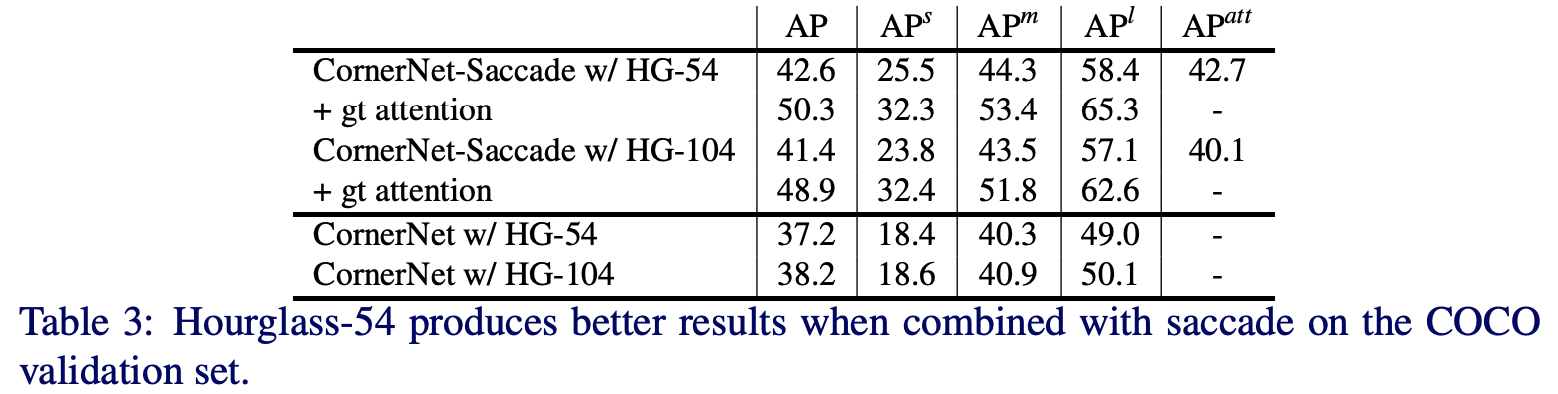
CornerNet-Saccade对比实验。

CornerNet-Squeeze对比实验。

目标检测的性能对比。
Conclusion
论文对CornerNet进行了性能优化,提出了CornerNet-Saccade和CornerNet-Squeeze两个优化的CornerNet变种,优化的手段具有很高的针对性和局限性,不过依然有很多可以学习的地方。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】






**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。