
大多数关于时间序列预测的文章都侧重于特定的聚合程度。但是,当我们能够深入分析聚合的数据,以便在更细粒度的层次上观察同一个序列时,挑战就出现了。在这种情况下,我们往往会发现,对较低水平的预测与总体预测并不一致。为了确保不会出现这种情况,我们可以采用一种称为分层时间序列(HTS)预测的方法。
理论介绍
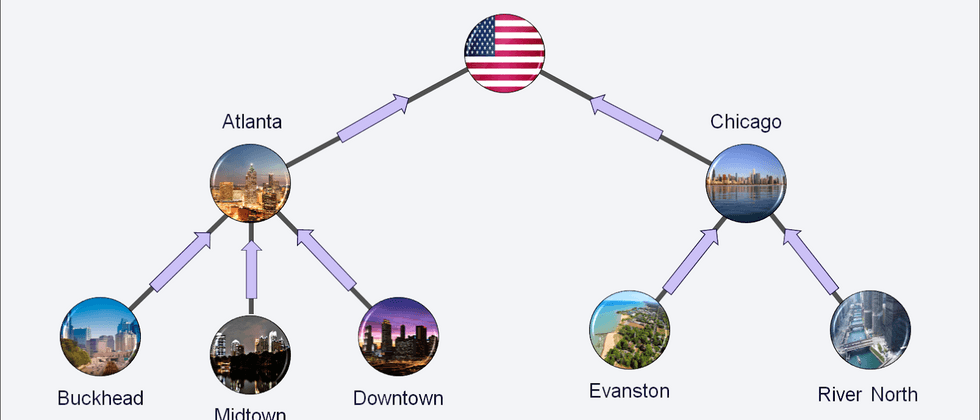
我们从数据开始介绍,在讨论聚合和分解的时间序列时,我们可以区分两种情况。通过分析一个例子可以很容易地理解它们:假设我们是一个在线零售商,在许多市场上销售不同种类的产品(比如亚马逊)。
第一种情况涉及数据的清晰的层次结构,其中较低的级别惟一地嵌套在较高级别的组中。最简单的例子就是地理上的分裂。作为零售商,我们可以查看所有市场的总销售额,然后按国家分类。如果有必要,我们可以更深入地研究每个地区的销售情况(比如美国各州等等)。当我们的数据遵循这样的结构时,我们就是在处理分层的时间序列。

第二种情况涉及时间序列,其中各级是交叉的,而不是嵌套的。作为一个零售商,我们可以有多层次的细节: 产品类别,价格范围,我们自己的产品相对于第三方销售的产品,等等。有了这样的分裂,就没有单一的“正确”的聚合方式。在这种情况下,我们使用分组的时间序列。

当然,当我们联合分析地理位置和产品类别时,分层和分组的时间序列可以混合成一个更加复杂的结构。
分级时间序列预测的全部挑战(这个名称还包括分组和混合案例,只是为了更清楚)是生成整个聚合结构的一致预测。所谓连贯性,我指的是以与基本聚合结构相一致的方式累加的预测。例如,所有区域的预测应该增加到国家水平,所有国家水平增加到更高的水平,等等。或者,可以调和不连贯的预测,使它们连贯一致。
还有一点需要澄清的是,层次化的时间序列预测本身并不是一种时间序列预测方法(如 ARIMA、 ETS 或 Prophet)。相反,它是不同技术的集合,使预测在给定的个人时间序列层次中一致。
下面,我们将介绍时间序列分层预测的主要方法。
自下而上的方法
在自下而上的方法中,我们预测层次结构的最细粒度级别,然后聚合预测以创建更高级别的估计。回到在线零售商的最初例子,我们将预测每个地区的销售额,然后将这些总和来创建对各自国家的预测。我们可以再次求和得到大陆/地区的水平,然后最终得到总和。
优点:
- 由于预报是在最低水平上获得的,因此不会因为汇总而失去信息。
缺点:
- 序列之间的关系(例如,不同地区之间的关系)没有被考虑
- 往往在高度聚合的数据上表现不佳
- 计算密集型(取决于任务和较低层级的级数)
- 数据中的噪音越大,预报的整体准确性就越差
自上而下的方法
自顶向下的方法包括预测层次结构的顶层,然后将预测分解为更细粒度的序列。最常见的是,历史比例是用来确定分裂。举个例子,我们可以预测总体水平。然后,看看过去的数据,我们可以推断美国占了销售额的50% ,欧洲占了40%。然后,我们可以迭代并将该系列分解为更细粒度的级别。
优点:
- 最简单的方法
- 对较高层次的预测是可靠的
- 只需要一个预报
缺点:
- 由于信息丢失(通过历史比例) ,较低水平的预测不太准确。
从中扩散的方法
从中扩散是上述两种方法的结合,只能用于严格分层的时间序列。在这种方法中,我们选择中间层并直接进行预测。然后,对于所选级别以上的所有级别,我们使用自下而上的方法ーー将级别向上加总。对于中间层以下的级别,我们使用自顶向下的方法。
由于这是两种不同方法之间的折衷,因此得出的预测不会丢失太多信息,而且计算时间也不会像自下而上的方法那样爆炸。
最优协调方法
上面描述的三种方法侧重于在单一水平上预测时间序列,然后使用这些来推断其余的水平。与之相反,在最优协调方法中,我们使用给定层次结构可以提供的所有信息和关系来预测每个级别。
在这种方法中,我们假设基础预测(对于所有级别的序列中的每个级别)近似满足层次结构。这意味着预测应该相对准确,而不是扭曲平衡。然后,我们使用线性回归模型来调和个别的预测。实际上,连贯的预测是所有各级基础预测的加权和。为了找到权重,我们需要解决一个方程组,以确保不同层次之间的层次关系被保留。
优点:
- 更准确的预测
- 以最少的信息损失在各级进行无偏预测
- 考虑到时间序列之间的关系
- 由于每个预测都是独立创建的,该方法允许在每个级别使用不同的预测方法(ARIMA、 ETS、 Prophet 等)。此外,不同的级别可以使用不同的特性集,因为某些变量在给定的粒度级别上可能不可用。
缺点:
- 最复杂的方法
- 可以是计算密集型的ー不能很好地适用于大量的级数
结论
在本文中,我简要介绍了层次时间序列预测,并描述了用于应对这一挑战的最流行的方法。一个显而易见的问题是使用哪种方法。你可能已经猜到了,答案是: 这要看情况。
前三种方法往往偏向于它们所预测的水平,这在直观上是有道理的。因此,当获得一个特定水平的准确预测是最重要的,我们希望获得其余作为副产品,我们可能希望从一个更简单的方法开始,看看我们是否满意。
否则,我们可能会研究在层次结构的所有级别上倾向于相当准确的最佳协调方法。理想情况下,我们可以尝试所有不同的方法,同时采用某种时间序列/交叉验证方案来评估每个方法的性能,并选择一个最适合我们的问题。
参考资料
原文作者:Eryk Lewinson 译者: Harry Zhu 英文原文地址:
https://towardsdatascience.com/introduction-to-hierarchical-time-series-forecasting-part-i-88a116f2e2作为分享主义者(sharism),本人所有互联网发布的图文均遵从CC版权,转载请保留作者信息并注明作者 Harry Zhu 的 FinanceR专栏:https://segmentfault.com/blog...,如果涉及源代码请注明GitHub地址:https://github.com/harryprince。微信号: harryzhustudio
商业使用请联系作者。






**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。