

一提到特征工程,我们立即想到是表格数据。但是我们也可以得到图像数据的特征,提取图像中最重要的方面。这样做可以更容易地找到数据和目标变量之间的映射。
这样可以使用更少的数据和训练更小的模型。更小的模型可以减少预测所需的时间。这在部署到边缘设备时特别有用。另一个好处是,可以更确定模型使用什么来进行这些预测。
本文将介绍使用Python进行图像特征工程的一些方法:
- Cropping
- Grayscalling
- Selecting RGB channels
- Intensity thresholds
- Edge detection
- Colour filters (给定的颜色范围内提取像素)
我们将在自动驾驶汽车上进行演示。如下图所示,轨道的图像训练一个模型。然后该模型将被用来做出预测,指导汽车行驶。本文的最后我们将讨论图像数据特征工程的局限性。
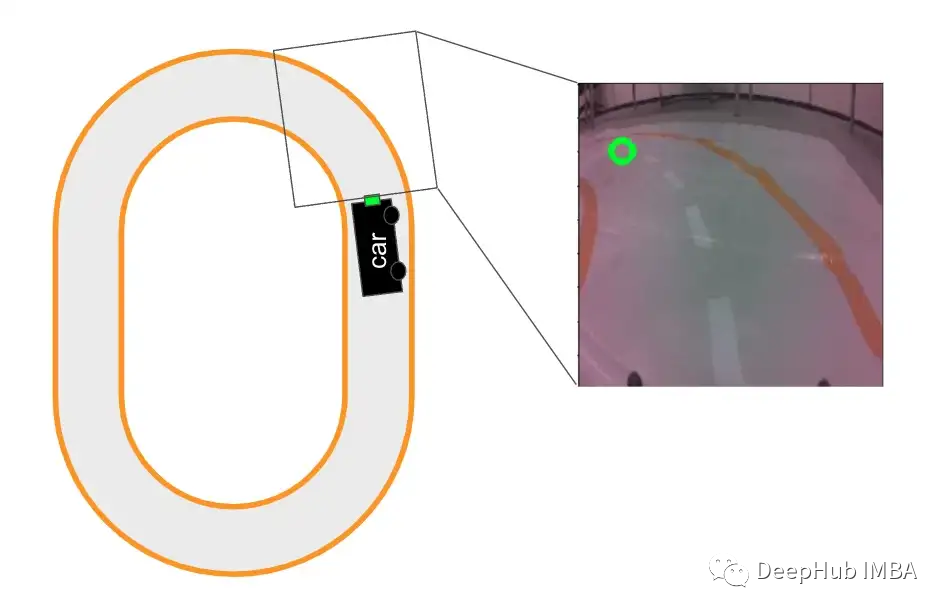
特性工程与增强
在深入研究之前,有必要讨论一下图像增强。该方法的目标与特征工程相似。但是它以不同的方式实现。
什么是数据增强?
数据增强是指我们使用代码系统地或随机地改变数据。对于图像,这包括翻转、调整颜色和添加随机噪声等方法。这些方法允许我们人为地引入噪声并增加数据集的大小。
在生产中,模型需要在不同的条件下执行。这些条件是由照明、相机的角度、房间的颜色或背景中的物体等变量决定的。
数据增强的目标是创建一个对这些条件的变化具有鲁棒性的模型。它通过添加模拟现实世界条件的噪声来实现这一点。例如,改变图像的亮度类似于在一天的不同时间收集数据。
通过增加数据集的大小,增强还允许我们训练更复杂的架构。或者说它有助于模型参数收敛。
图像数据特征工程
特征工程的目标是与增强是相似的,也就是想要创建一个更健壮的模型。但是不同的是,它删除了任何对准确预测没有必要的噪音。也就是去掉了在不同条件下会发生变化的变量(这正好与增强相反)。
通过提取图像中最重要的部分简化了问题。这允许使用更简单的模型架构。我们可以使用更小的数据集来找到输入和目标之间的映射。
另外一个重要的区别是如何在生产中处理这些方法。你的模型不会对增强图像做出预测。但是使用特征工程,模型将需要在它训练的相同特征上做出预测。这意味着必须能够在生产环境中进行相同的特性工程。
使用Python进行图像特征工程
下面我们开始进入正题,让我们开始进行特性工程的操作。
我们有一些标准包(第2-3行)。Glob用于处理文件路径(第5行)。我们也有一些包用于处理图像(第7-8行)。
import numpy as np
import matplotlib.pyplot as plt
import glob
from PIL import Image
import cv2我们这里将使用用于为自动驾驶汽车提供方向路径的图像。你可以在Kaggle上找到这些例子。用下面的代码加载其中一个图像。首先加载所有图像的文件路径(第2-3行)。然后加载(第8行)并在第一个路径上显示图像(第9行)。可以在图1中看到这个图像。
#Load image paths
read_path = "../../data/direction/"
img_paths = glob.glob(read_path + "*.jpg")
fig = plt.figure(figsize=(10,10))
#Display image
img = Image.open(img_paths[0])
plt.imshow(img)
Cropping
裁剪图像以去除不需要的外部区域,目的是只删除图像中不需要进行预测的部分。对于自动驾驶汽车可以从背景中移除像素。
加载一张图像(第2行)。然后将这张图像转换为一个数组(第5行)。这个数组的尺寸为224 x 224 x 3。图像的高度和宽度为224像素,每个像素都有一个R G B通道。为了裁剪图像,我们只选择y轴上位置25以上的像素(第8行)。结果如图2所示。
#Load image
img = Image.open(img_paths[609])
#Covert to array
img = np.array(img)
#Simple crop
crop_img = img[25:,]
如果需要保持纵横比。可以通过将不需要的像素变为黑色(第3行代码)来实现类似的结果。

通过裁剪,我们删除了不必要的像素,这样可以避免模型对训练数据的过度拟合。例如,背景中的椅子可能出现在所有左转处。该模型有可能将这些与左转预测联系起来。
上面的图片,还可以进一步处理,比如可以在不删除任何轨道的情况下裁剪图像的左侧。但是在下图中我们要删除重要的轨道部分。
crop_img = np.array(img)
crop_img[:25,] = [0,0,0]
crop_img[:,:40] = [0,0,0]
为什么这样做呢?这又回到了特性工程需要在生产环境中进行的问题上。你不知道什么图像将在什么时间显示给模型。这意味着需要对所有图像应用相同的裁剪功能,需要确保它永远不会删除图像的重要部分,但这是不可能的,所以我们才需要模拟这样的情况。
Grayscale
gray_img = cv2.cvtColor(img,cv2.COLOR_RGB2GRAY)
灰度化是通过捕捉图像中的颜色强度来实现的。它通过取RGB通道的加权平均值来实现这一点。我们使用这个公式:
Y = 0.299 r + 0.587 g + 0.114* b
如果我们使用所有的RGB通道,它将由150,528个值(2242243)组成。对于灰度图像,我们现在只有50,176个值(224*224)。更简单的输入意味着需要更少的数据和更简单的模型。
RGB channels
RGB通道中,一个通道可能更重要。我们可以不进行灰度化,而是直接只使用该通道。例如下面,我们选择R(第6行)、G(第7行)和B(第8行)通道。每个生成的数组的尺寸都是224 x 224。您可以在图6中看到相应的图像。
#Load image
img = Image.open(img_paths[700])
img = np.array(img)
#Get rgb channels
r_img = img[:, :, 0]
g_img = img[:, :, 1]
b_img = img[:, :, 2]
这里还可以使用channel_filter函数。通道参数(c)的值为0、1或2,这取决于你想要哪个通道。但是有一点,不同的python包将以不同的顺序加载通道。这里我们使用的PIL是RGB。如果使用cv2.imread()加载图像,通道将按BGR顺序排序。
def channel_filter(img,c=0):
"""Returns given channel from image pixels"""
img = np.array(img)
c_img = img[:, :, c]
return c_img使用灰度或者RGB的通道选择,就需要考虑是否要从图像中删除了重要信息。但是对于本文中的轨道示例,轨道是橙色的,所以没有问题,轨迹的颜色有助于将其与图像的其他部分区分开来。这也是在实际应用是需要考虑的。
Intensity threshold
使用灰度化,每个像素的值将在0到255之间。我们可以通过将输入转换为二进制值来进一步简化输入。如果灰度值高于一个阈值,像素值为1,否则为0。我们称之为强度阈值。
下面的函数用于应用该阈值。首先对图像进行灰度化(第5行)。如果像素高于阈值,那么它将被设置成1000(第8行)。如果像素值低于阈值将被设置为0(第9行)。最后还将再次缩放所有像素,使它们的值为0或1(第11行)。
自动驾驶汽车项目的一部分是为了避开障碍物。在图7中,可以看到如何应用强度阈值函数,我们可以将这个黑色的罐头障碍物从图像中分隔离出来。

这里的截断值可以看作是一个超参数。更大的截断意味着我们包含更少的背景噪声。但是缺点是我们捕获的范围更小。
Edge detection
如果想分离轨道,可以用更精细边缘检测方法。这是一种用于检测图像边缘的多级算法。
这里我们使用cv2.Canny()函数应用该算法。其中threshold1和threshold2为滞回过程参数。这是边缘检测算法的最后一个过程,用于确定哪些线是真正的边。
#Apply canny edge detection
edge_img = cv2.Canny(img,threshold1 = 50, threshold2 = 80)就像强度阈值一样,我们留下了一个二进制映射-白色表示边,黑色表示其他。这条轨迹现在更容易与图像的其他部分区分开来。但是可以看到背景中的边缘也被检测到了。

Colour filter
如果我们用像素颜色来隔离轨迹,可能会有更好的结果。使用下面的pixel_filter函数来做到这一点。cv2.inRange()将图像转换为二进制映射(第10行)。这个函数检查像素是否在lower(第5行)和upper(第6行)列表给出的范围内。具体来说,每个RGB通道必须在各自的范围内(例如134-t≤R≤194+t)。
def pixel_filter(img, t=0):
"""Filter pixels within range"""
lower = [134-t,84-t,55-t]
upper = [192+t,121+t,101+t]
img = np.array(img)
orange_thresh = 255 - cv2.inRange(img, np.array(lower), np.array(upper))
return orange_thresh简单来说,该函数确定像素颜色是否与轨道的橙色足够接近。可以在图9中看到结果。参数t引入了一些灵活性。使用更高的值可以捕获更多的轨道,但会保留更多的噪音。这是因为背景中的像素也会落在这个范围内。

我们从哪里得到下界和上界呢?也就是说我们怎么知道会落在[134,84,55]和[192,121,101]之间?如果你有兴趣,我们将在后面的文章中解释。
在图10中,可以看到正在运行的选择器。从多个图像中选择像素,并尝试在轨道上的不同位置选择它们。这样我们就能在不同的条件下得到完整的像素值。
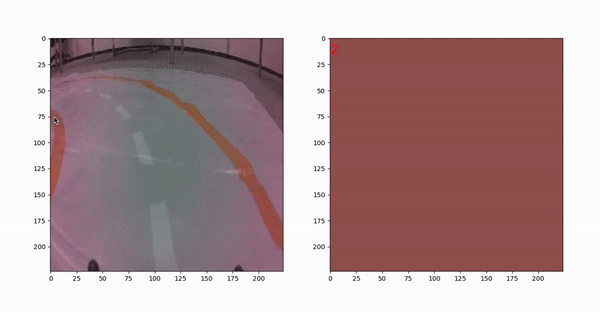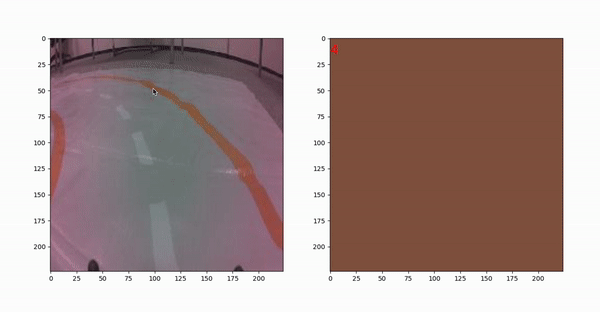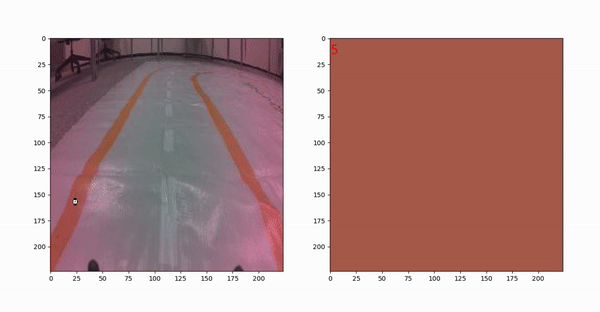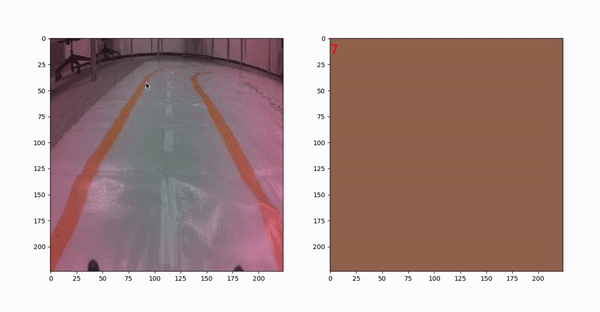
我们一共选了60种颜色。可以在图11中看到所有这些。所有这些颜色的RGB通道存储在一个列表变量-“colours”中。

最后,我们为每个RGB通道取最小值和最大值。这就给出了下界和上界。
lower = [min(x[0] for x in colours),
min(x[1] for x in colours),
min(x[2] for x in colours)]
upper = [max(x[0] for x in colours),
max(x[1] for x in colours),
max(x[2] for x in colours)]特征工程的局限性
上面就是对于图像数据基本的特征工程,但是你可能觉得这些方法并不那么太好用。这是因为深度学习的一个主要好处是它可以识别复杂的模式,而不需要进行特征工程。你需要弄清楚图像的哪些方面是重要的,然后编写代码来提取这些方面,这在神经王罗出现以后变得不那么重要了。
另外对于一些方法,我们已经看到无法消除所有的噪声。例如,黑色背景中的噪声和对象像素具有相同的值。这些都是手动的特征不足之处。
但是手动提取特征在处理相对简单的计算机视觉问题时时非常有用的。例如这个无人驾驶的小车,我们的轨迹从未改变,物体的颜色总是一样的,这样可以加快运行速度核准确性。而对于更复杂的问题,我们需要更多的数据,或者使用深度学习的方法进行复杂的模式识别。
https://avoid.overfit.cn/post/bd8d9a344381437d92d8b2f714359332
作者:Conor O'Sullivan







**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。