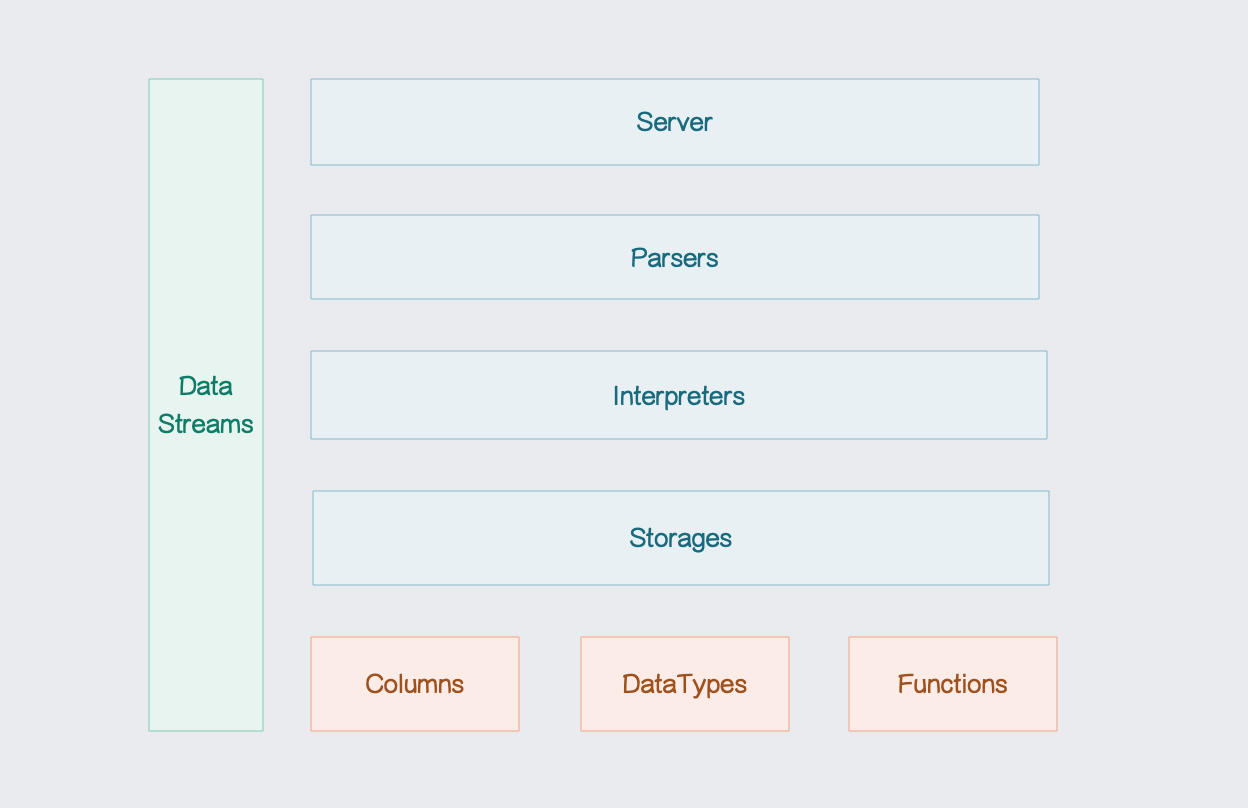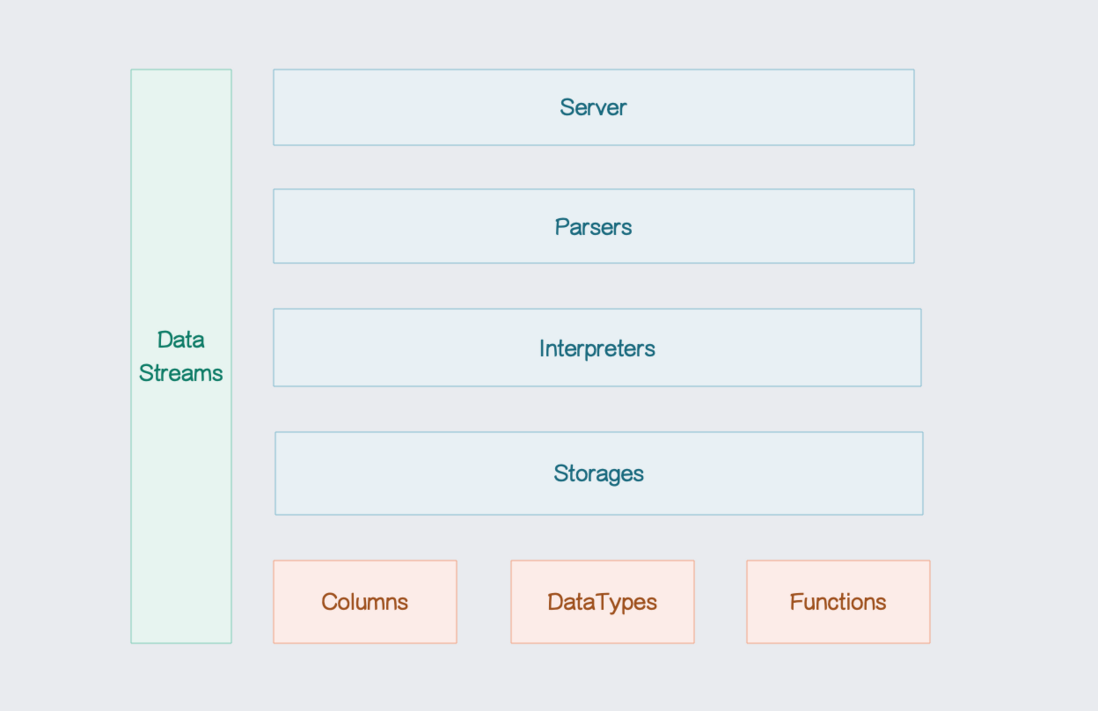
ClickHouse是一个用于联机分析处理(OLAP)的开源列式数据库。... 阅读全文
3 人点评

501-1000 人
最快开源 OLAP 引擎
最喜欢哪些功能,好在哪里?
- 多个服务器上的分布式处理:分布式查询:从分布式表查询-> 重写 ->负载均衡,发送给远程节点查询->接收结果、合并
- 非常快速的扫描,可用于实时查询
- 列存储非常适合使用“宽”/“非规范化”表(许多列):计算类查询时,大大减少IO消耗
- 压缩性好:相对mysql压缩10倍
- SQL支持(有限制)
- 良好的功能集,包括支持近似计算
- 不同的表引擎:MergeTree,ReplicatedMergeTree,Distributed等
- 非常适合结构日志/事件数据以及时间序列数据(引擎MergeTree需要日期字段)
- 索引支持(仅限主键,不是所有存储引擎)
- 漂亮的命令行界面,具有用户友好的进度条和格式
不喜欢哪些功能,缺点或不足是什么?
- 没有真正的删除/更新支持,也没有事务(与Spark和大多数大数据系统相同),没有delete/update
- 没有二级密钥(与Spark和大多数大数据系统相同)
- 只支持自己的协议(没有MySQL协议支持)
- 有限的SQL支持,以及连接实现是不同的。如果要从MySQL或Spark迁移,则可能必须使用连接重新编写所有查询。
- 没有窗口功能。
他解决了你的哪些问题?
高吞吐写入能力