
这样的 CSS 样式 #nav ul li {...},浏览器渲染方式是 li -> ul -> #nav,所以效率低,可是为什么不从左往右找呢?
为什么 CSS 选择器解析的时候是从右往左?
阅读 18.5k

终究还是要了解 浏览器的工作原理。
简言之就是 浏览器css匹配核心算法的规则是以 right-to-left 方式匹配节点的。
这样做是为了使规则能够快、准、狠地与render树上的节点匹配,通俗地将就是 就近原则。
试想一下,如果采用 left-to-right 的方式读取css规则,那么大多数规则读到最后(最右)才会发现是不匹配的,这样会做费时耗能,最后有很多都是无用的;而如果采取 right-to-left 的方式,那么只要发现最右边选择器不匹配,就可以直接舍弃了,避免了许多无效匹配。
显而易见,right-to-left 比 left-to-right 的无效匹配次数更少,从而匹配快、性能更优,所以目前主流的浏览器基本采取right-to-left的方式读取css规则。
可以参考问题 Why do browsers match CSS selectors from right to left?

從左往右難道不會效率更低?
很顯然瀏覽器的渲染方法類似於數學中的篩法——列出全部自然數(很容易),刪掉2的倍數、3的倍數、5的倍數、7的倍數。。。
瀏覽器先列出所有 li(很容易),再刪掉父元素不是 ul 的,再刪掉 ul 的父元素不是 #nav 的~
如果從左往右找,假如有一萬個 #nav(當然這是不可能滴),每個 #nav 下面有 10000 個 div,只有第 10000 個 #nav 裏有 ul,那麼瀏覽器要先遍歷 99990000 個元素才能找到想要的!
即便 #nav 一定是唯一的,#nav 下的 ul 也不一定唯一,而又沒辦法直接列出 #nav 下面的 li,所以 #nav 唯一這個條件沒法用(即便用,還是要經歷從右往左的過程。。。)
瀏覽器的渲染算法不一定是某些特殊情況效率最高的,但至少要是絕大多數情況都不會太差的。因爲速度這個東西很容易被拖後腿(就像木桶效應),所以後者纔更接近全局最優~
撰写回答
你尚未登录,登录后可以
- 和开发者交流问题的细节
- 关注并接收问题和回答的更新提醒
- 参与内容的编辑和改进,让解决方法与时俱进
被 2 篇内容引用


推荐问题
CSS如何让指定的某个Tag不显示(比如:display=none),但是还是占有位置呢?
参考使用:antd的Tag我做了2行的Tag: {代码...} 现在的需求是,如何让指定的某个Tag不显示(比如:display=none),但是还是占有位置呢?3 回答1k 阅读✓ 已解决
如何实现类似豆包的AI改写框跟随内容滚动效果?
豆包这种是怎么实现的,ai改写这个框是跟随内容滚动的,但是ai改写这个框是在body下与根节点平级的,想了半天,看他页面上代码也看不出来,求助4 回答1.3k 阅读✓ 已解决
body :first-child(不是body:first-child,中间有空格)伪类选择器到底选中了什么元素?
:first-child 选中了什么如题,在学习:first-child伪类的时候,我使用如下语法,但是产生的结果在预料之外。codepen链接html {代码...} css {代码...} 按照:first-child语法,body :first-child选中的应该是body的第一个子元素,也就是 {代码...} 结果选中了这个元素 {代码...} 网上搜索无果,所以来这里提问了,body :f...2 回答950 阅读✓ 已解决
如何在CSS中实现滚动条不溢出圆角框?
请问css如何实现滚动条在外侧滚动框的下一层?我最近在设计一个小插件,里面有一个换肤的小弹窗,小弹窗里还有一个小框,在这个小框里加了滚动条,小框为了美化做了border-radius,然后为这个框自定义了::webkit-scrollbar伪类,但是我发现这个滚动条会溢出这个框,很不好看,下图为现在的效果:我想做到上下的滚动条可...2 回答1.4k 阅读✓ 已解决
请问,是否可以设定Table的宽度,或者不让其超过父容器呢?
我写了一个可编辑Cell的List: {代码...} 使用方式: {代码...} 现在的问题是,比如:内容过长会直接冲出父容器:请问,是否可以设定Table的宽度,或者不让其超过父容器呢?2 回答1.1k 阅读✓ 已解决
如何在Ant Design表格中同时设置scroll.x和scroll.y且表头不换行?
当同时设置scroll.x='max-content'和scroll.y的值,并将表头的文字内容设置到比列内容长且列未设置固定宽度时,表头会换行收缩。2 回答2.6k 阅读
表数据复制一条添加到数据库,前端跳转到数据所在的page页,滚动到对应行并添加高亮样式异常?
现在的情况是点击菜单切换表数据后点击copyCell方法复制数据,然后执行getData获取新的表数据。当我第一次点击复制,跳转到了对应的page页,高亮的class名称在,高亮效果不显示,当我第二次点击复制,这个高亮效果显示。第三次点击复制,高亮不显示,第四次显示,以此类推,这种情况该怎么解决?1 回答1.1k 阅读✓ 已解决
CSS 的后代选择器本身就是一种在标准里面
不那么推荐的方式。那为什么从右向左的规则要比从左向右的高效?
如图:
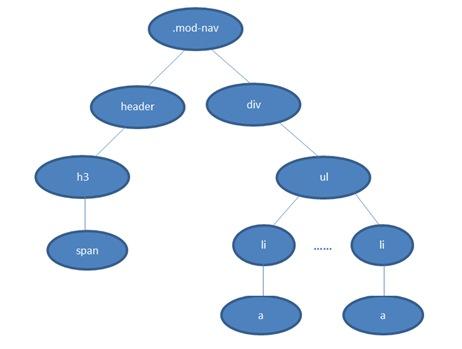
假如 DOM 的结构如上图,匹配规则是 .mod-nav h3 span。
若从左向右的匹配,过程是:从 .mod-nav 开始,遍历子节点 header 和子节点 div,然后各自向子节点遍历。在右侧 div 的分支中,最后遍历到叶子节点 a ,发现不符合规则,需要回溯到 ul 节点,再遍历下一个 li-a,假如有 1000 个 li,则这 1000 次的遍历与回溯会损失很多性能。
再看看从右至左的匹配:先找到所有的最右节点 span,对于每一个 span,向上寻找节点 h3,由 h3再向上寻找 class=mod-nav 的节点,最后找到根元素 html 则结束这个分支的遍历。
很明显,两种匹配规则的性能差别很大。之所以会差别很大,是因为从右向左的匹配在第一步就筛选掉了大量的不符合条件的最右节点(叶子节点);而从左向右的匹配规则的性能都浪费在了失败的查找上面。
当然这是比较明显情况,如果在叶子上存在多个不符合条件的 span,从右向左的规则也会走一些弯路(这时就需要优化 CSS 选择器了)。但平均来说它还是更高效,因为大多时候,一个 DOM 树中,符合匹配条件的节点(如 .mod-nav h3 span)远少于不符合条件的节点。
此段转载自:http://www.cnblogs.com/zhaodongyu/p/3341080.html 经过编辑及排版。
但是后来人们发现这种方式很不符合人类自然的思考方式,所以在建造 web 的时候更喜欢采用看起来比较有条理的更加像后端程序的层次结构方式命名,类似
#fuck .you a {...}。但是根据实践,大家发现这样基本是在
自high,因为别人在改 CSS 的时候是不会去看你写的 CSS 的,都是直接浏览器定位到位于哪一行,直接过去改代码块,反正一眼就能看懂。