
这个问题源于此贴。http://segmentfault.com/q/10100000001...,源于@Sunny 三楼回答的“干扰串“http://www.awflasher.com/jsmail。在这里贴出实际工作的源码:
function htmlEncode( s )
{
var result = "";
for (var j = 0; j < s.length; j++ ) {
// Encode 25% of characters
if (Math.random() < 0.25 || s.charAt(j) == ':' || s.charAt(j) == '@' || s.charAt(j) == '.') {
var charCode = s.charCodeAt(j);
result += "&#";
result += charCode;
result += ";";
} else {
result += s.charAt(j);
}
}
return result;
}
function urlEncode( s )
{
var HEX = "0123456789ABCDEF";
var encoded = "";
for (var i = 0; i < s.length; i++ ) {
// Encode 25% of characters
if (Math.random() < 0.25) {
var charCode = s.charCodeAt(i);
encoded += "%";
encoded += HEX.charAt((charCode >> 4) & 0xF);
encoded += HEX.charAt(charCode & 0xF);
} else {
encoded += s.charAt(i);
}
} // for
return encoded;
}
function Obfuscate()
{
var plaintext = document.TheForm.F1.value;
var result = "<a href='";
result += htmlEncode("mailto:" + urlEncode(plaintext) );
result += "'>";
result += htmlEncode(plaintext) ;
result += "</a>";
document.TheForm.F2.value = result;
if (document.all) {
document.all.RESULT.innerHTML = "最终效果: " + result;
} else {
document.getElementById("result").innerHTML = "最终效果: " + result + " (注意观察状态栏,这可是标准的mailto链接哦)";
}
return false; /* Privacy note: returning false prevents the browser from posting your email address! */
}我对源码的理解是,htmlEncode将本来在网页中显示的正常字符转变为html实体;urlEncode则将原来页面中href属性中的url编码为utf8格式,相当于使用了encodeURI,但是这里不使用encodeURI的原因是作者希望能够只将大约25%的字符串转义,从而加大破译者的难度。
我的问题是:
- 代码中使用了html实体其中一种表示方式&#X;其中X为的unicode编码。而通过方法atCharCode可以获得某个字符的unicode编码。问题是,当我查阅到表一(见下)时发现似乎空格是一个例外,通过atCharCode获得的值是32,而它的html实体是
 ,请问这是什么原因? - urlEncode将unicode转化为utf8的方式让我觉得奇怪。http://cattail2012.wordpress.com/2012...。该文章是我对于字符集和编码的认识,其中一小节(相关应用)中介绍了对于unicode到utf8的转换。不知道是我错了还是作者代码存在缺陷?
表一
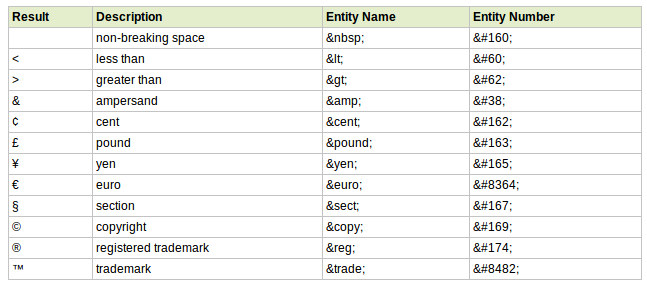
第一个问题: 和空格在unicode里是2个不同的字符。空格的编码是32,Non-breaking space的编码是160。在HTML文本里,如果遇到多个连续的空格字符,浏览器会把它们合并成一个空格字符,而对于多个连续的 就不做合并。
第二个问题:作者写urlEncode这个函数的目的是用来编码email地址的,而email地址只可能是ASCII字符集里的字符,UTF-8里对ASCII字符的编码规则与ASCII字符集是一样的,所以可以使用这种方式来编码。显然,用这种方式去编码超出ASCII字符集之外的字符,例如中文,是不行的。你的理解没错,作者这样写也没错,关键是看打算用在什么地方。